
Tägliches Üben ist für das Erlernen einer Sprache unerlässlich und Duolingo motiviert Sprachenlernende mit täglichen Übungserinnerungen, am Ball zu bleiben. Duos Hartnäckigkeit ist sogar so bekannt, dass daraus beliebte Internet-Memes entstanden sind. Und seien wir ehrlich: Die meisten von uns haben wahrscheinlich schon einmal eine dieser Benachrichtigungen weggewischt ... und sich dabei vermutlich ein bisschen schuldig gefühlt!
Hast du dich allerdings schon einmal gefragt, wie Duo eigentlich entscheidet, welche Benachrichtigung er als Nächstes versenden soll? Nun ja, letztes Jahr haben Duolingos Ingenieure für maschinelles Lernen ein ziemlich kluges KI-System entwickelt, mit dessen Hilfe sie täglich für jeden Lerner genau die richtige Übungserinnerung finden können! Diesen neuen Algorithmus haben wir in einem Paper auf der Knowledge Discovery and Data Mining (KDD) Conference 2020 veröffentlicht. In diesem Beitrag werfen wir einen Blick auf die KI hinter diesen berüchtigten Benachrichtigungen.
Kurz und bündig
Wir verwenden eine Reihe an vorformulierten Übungserinnerungen und passen diese dann gezielt je nach Sprache und Lernfortschritt an. Außerdem aktualisieren wir die Benachrichtigungen regelmäßig, damit sie aktuell und ansprechend bleiben. Und da das Testen von Neuheiten bei Duolingo das A und O ist, überprüfen wir immer erst, wie neue Benachrichtigungen bei einer kleinen Anzahl von Lernenden ankommen, bevor wir sie an alle senden. So gelangt nur eine Auswahl der besten Vorlagen in den Pool von Übungserinnerungen.
Die Übungserinnerungen wurden bis dahin nach dem Zufallsprinzip aus dem Pool ausgewählt und versendet. Wir fragten uns, ob wir das ganze intelligenter gestalten und so unsere Lernenden noch besser motivieren könnten: Was wäre, wenn wir täglich mithilfe von KI die beste Benachrichtigung für jeden einzelnen Lerner finden könnten? Und so machten sich letztes Jahr unsere Ingenieure für maschinelles Lernen daran, ein maßgeschneidertes KI-System zu entwickeln, das genau dazu in der Lage ist.
Bandit-Algorithmen
Um besser zu verstehen, wie Lernende auf unterschiedliche Benachrichtigungen reagieren, haben wir angefangen, mit Bandit-Algorithmen zu experimentieren. Bandit-Algorithmen sind eine Form von KI, bei der ein Algorithmus wiederholt zwischen denselben Optionen wählen muss und kontinuierlich aus zuvor getroffenen Entscheidungen lernt, welche Optionen am besten sind – also welche unserer Benachrichtigungen die Lernenden am ehesten dazu bringen, ihre Sprache zu üben.
Um zu verstehen, wie Bandit-Algorithmen funktionieren, stell dir vor, dass du dich in einem Raum mit Spielautomaten befindest. Du erhältst eine Tasche voller Spielmarken, mit denen du an den Spielautomaten spielen kannst, wobei einige Automaten mehr auszahlen als andere. Da du herausfinden möchtest, welche der Automaten mehr zahlen, spielst du an vielen verschiedenen Automaten und beobachtest, wie viel jeder einzelne auszahlt. Mit der Zeit verschaffst du dir einen Eindruck davon, welche Automaten am meisten auszahlen – und beginnst, häufiger an diesen zu spielen.
Unser Bandit-Algorithmus nutzt eine ganz ähnliche Strategie, aber anstelle von Spielautomaten wählt er Benachrichtigungen aus und seine „Auszahlung“ besteht darin, Lernende dazu zu bringen, eine Lektion abzuschließen. Im Grunde genommen funktioniert er wie folgt:

Data Science: Woher wissen wir, welche Vorlagen die besten sind?
Damit die Bandit-Algorithmen für unsere Benachrichtigungen funktionieren, mussten wir jedoch eine Reihe neuer datenwissenschaftlicher Probleme lösen. Zunächst sammelten wir Daten, und zwar die Ergebnisse von etwa 200 Millionen Übungserinnerungen, die über einen Zeitraum von 34 Tagen versendet wurden. Anhand dieser Daten konnten wir analysieren, welche Benachrichtigungen die Lernenden am ehesten ansprachen.
Unser Ziel war es, jede Benachrichtigung danach zu bewerten, wie viele Lernende eine Lektion nach ihrem Erhalt abgeschlossen haben. Eine besondere Herausforderung bestand darin, verschiedene Benachrichtigungen für unterschiedliche Zielgruppen zu konzipieren: Einige Benachrichtigungen sind beispielsweise nur dann sinnvoll, wenn Lernende eine Streak-Wette eingegangen sind, und andere können nur montags verschickt werden. Andererseits schließen manche Lernende eine Lektion unabhängig von den erhaltenen Benachrichtigungen ab (vor allem, wenn sie unglaublich lange Streaks haben). Dadurch haben Benachrichtigungen für diese Zielgruppen einen unfairen Vorteil! Um die Vorlagen fair zu bewerten, haben wir eine neue Methode entwickelt, um jede Benachrichtigung nur mit denen zu vergleichen, die an dieselbe Art von Lernenden gesendet wurden.
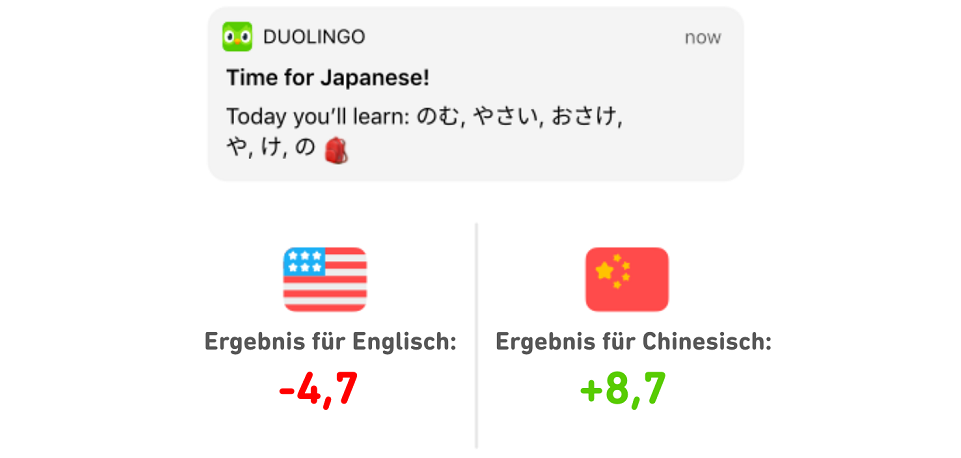
Nachdem wir die Benachrichtigungen auf diese Weise analysiert hatten, stellten wir fest, dass nicht nur manche Übungserinnerungen viel besser funktionierten als andere, sondern dass auch die Ausgangssprache der Lernenden entscheidend war: Zum Beispiel stößt die Übungserinnerung „Zeit für [Sprache]“ besonders bei Chinesischsprachigen auf Resonanz, kommt aber weniger gut bei Englischsprachigen an. Diese Unterschiede bedeuten, dass wir mehr Lernende zum Üben motivieren können, wenn wir die Benachrichtigungen auf die jeweilige Ausgangssprache abstimmen.
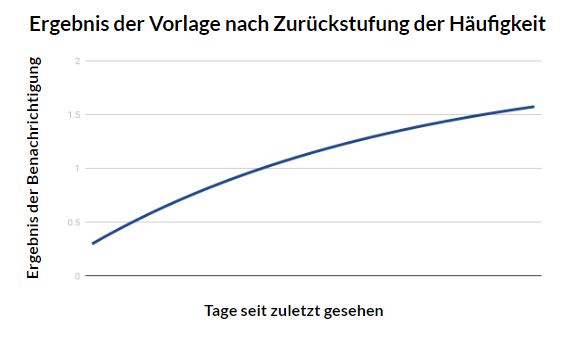
Doch bevor wir diese Erkenntnisse in einen brauchbaren Bandit-Algorithmus integrieren konnten, mussten wir auch den „Neuigkeitseffekt“ berücksichtigen: Wir stellten die Hypothese auf, dass ganz neue Benachrichtigungen, also solche, die Lernende zum ersten Mal sehen, aufgrund der Neuheit besonders überzeugend sind – dass dieser Effekt jedoch irgendwann verpufft und die Lernenden dann eine andere Art von Benachrichtigungen brauchen, die sie zum Üben motiviert. Diese Hypothese konnten wir schließlich anhand der Daten aus den etwa 200 Millionen Übungserinnerungen bestätigen. Das beste Ergebnis erzielten wir also, wenn dieselbe Benachrichtigung nicht zu oft verwendet wurde.
Das widerspricht jedoch der Funktionsweise herkömmlicher Bandit-Algorithmen: Sie machen die beste Option ausfindig und verwenden diese dann immer wieder. Um dies zu korrigieren, mussten wir dem KI-Algorithmus explizit beibringen, dass unsere Lernenden es nicht mögen, dieselbe Benachrichtigung zu oft zu sehen. Das taten wir, indem wir Erinnerungen, die bereits zuvor gesehen wurden, zurückstuften. Die Abstände zwischen den Wiederholungen einer Benachrichtigung haben wir anhand der gleichen Vergessenskurve festgelegt, die wir auch zum Messen des Lernens von Wörtern verwenden!
Schnelle Datenverarbeitung im großen Stil!
Wir mussten den Bandit-Algorithmus schneller gestalten, damit er dazu in der Lage war, die Millionen von Übungserinnerungen zu verarbeiten, die täglich an unsere Lernenden gesendet werden. Außerdem musste der Algorithmus eine große Menge an Daten verarbeiten: Das System produziert mehrere Millionen Datensätze pro Woche, die analysiert werden müssen. Um diese Datenmengen verarbeiten zu können, nutzen wir Big-Data-Tools wie AWS Kinesis Firehose und Spark.
Fazit
Als wir unseren Bandit-Algorithmus in der realen Welt testeten, konnten wir innerhalb weniger Wochen feststellen, dass mehr Lernende die Lektionen häufiger beendeten. Und er war besonders erfolgreich darin, Zehntausenden von neuen Lernenden dabei zu helfen, zu ihren Lektionen zurückzukehren und so eine Lernroutine aufzubauen – eine der schwierigsten Aufgaben beim Sprachenlernen! Darüber hinaus konnten wir die Erkenntnisse unserer KI nutzen, um zukünftige Benachrichtigungen besser zu gestalten und so Lernende noch mehr zum Üben zu motivieren! Im Herbst erfährst du mehr darüber, wie wir unsere Benachrichtigungen schreiben.
Du arbeitest gern an solchen und ähnlichen Aufgaben? Dann steig bei uns ein! Auf unserer Karriereseite erfährst du mehr über unsere Stellen in den Bereichen Softwaretechnik, Data Science und Machine Learning.