“Test everything.” This is one of the key operating principles that we follow at Duolingo in order to continuously improve the learning experience for our users. It means we rely heavily on experiments and data to help us make informed decisions about any updates or new features we launch.
Experimentation has always been core to how Duolingo operates. On a given week, it’s not uncommon for us to have a few hundred experiments running simultaneously. We conduct experiments for any changes we want to make to Duolingo—from seemingly small ones like updating a single button in the app to rolling out a major feature like Leaderboards.
Running as many experiments as we do all at once doesn’t come without caveats, though. A big one is determining how to best gather and synthesize the data points that emerge from each experiment, which in turn gives us a better understanding of which changes we should (or shouldn’t) make.
To help solve for this, we developed an internal, company-wide experiments service that has been one of our secret weapons in helping us to constantly improve the Duolingo experience. Since launching this service three years ago (and updating it continuously since then), we have run over 2,000 experiments in total and released thousands of new or updated features.
Why and how do we run experiments?
Think of any feature that you’ve come across while using Duolingo. Animated skill icons? The result of an experiment. Adding five new leagues to the Leaderboard? Also the result of an experiment. The amount of tears that our owl mascot, Duo, cries in your inbox when you forget to do your lessons? You guessed it.
Every experiment we conduct provides us with valuable data and information that we use to continually improve the Duolingo experience for learners. Specifically, our experiments follow the A/B testing method, where a certain portion of learners are placed into an A group (the control group) while others are placed into a B group (the experiment group); the A group sees the current version of the product, while the B group sees the new or updated feature. Then, based on several metrics, whichever group seems to respond more positively indicates the version that we should move forward with for all learners. We use the A/B testing approach for two main reasons: 1) it helps us make data-driven product decisions, and 2) if a change doesn’t turn out as well as we had hoped, it gives us the opportunity to learn and iterate.
Our experiments service provides a simple, user-friendly interface for setting up these groups, as well as a clear visualization of the key metrics that we would need to know in order to decide how to best move forward with any given experiment.
What do our experiments look like?
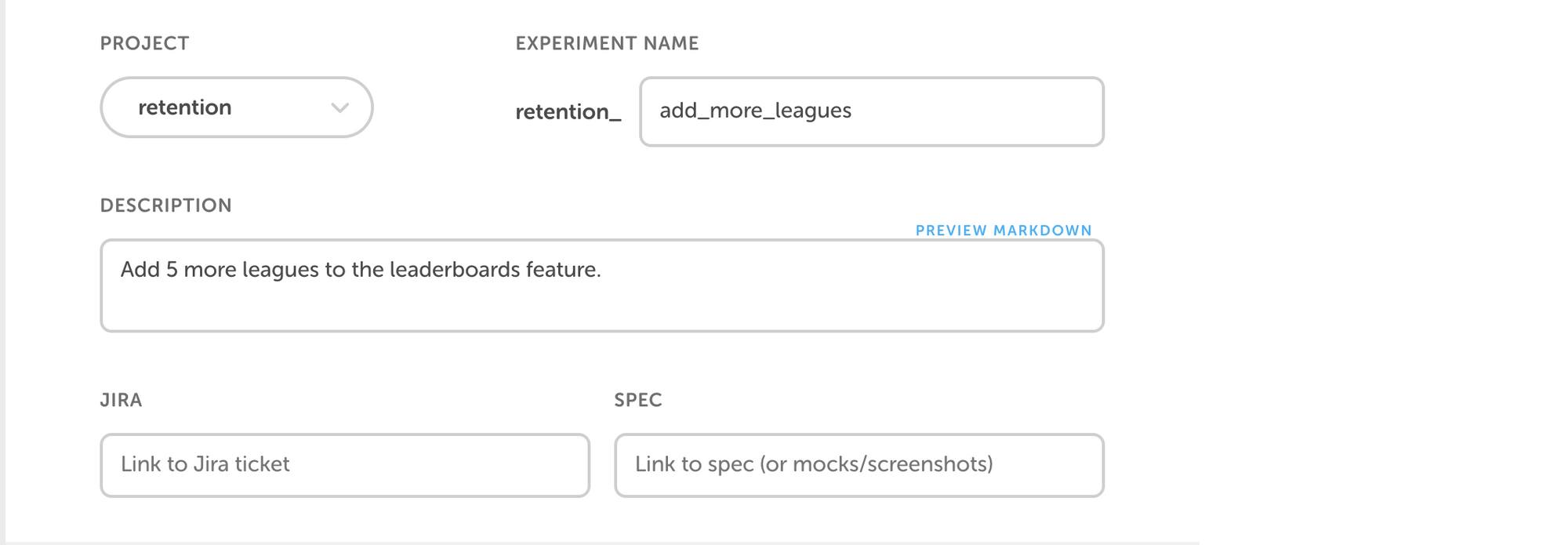
While no two experiments we run are the same, each one comes with a set of key decisions that need to be made, which our experiments service helps to outline. These decisions typically fall into four categories:
- What does the experiment do?
- How many arms does the experiment need, and what do those look like?
- Who should see the experiment?
- What types of results are expected?
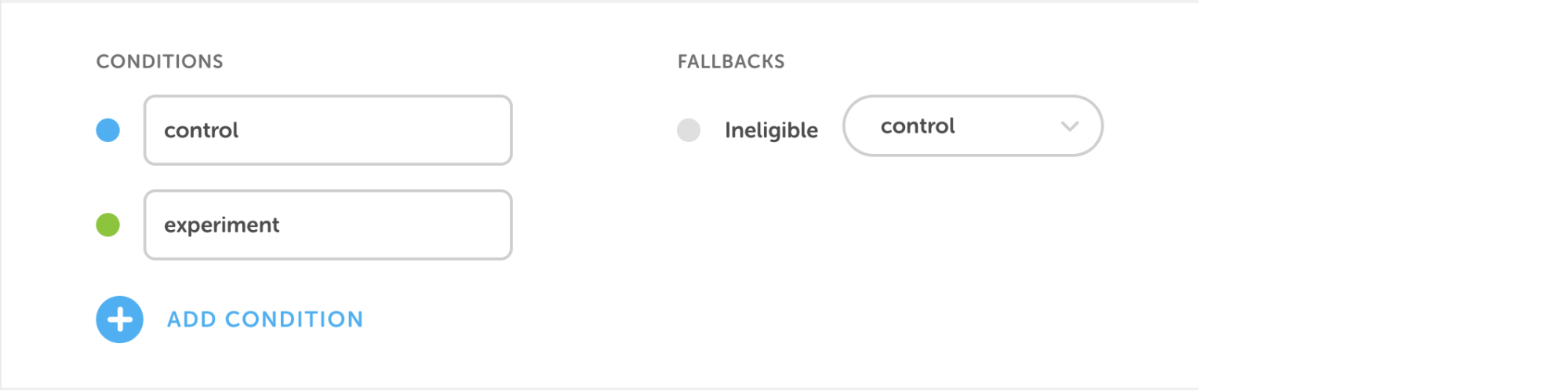
Once we determine the goal of an experiment, we then need to decide how to build out the experiment groups. While some experiments only require two groups (the standard “control” and “experiment”), other experiments might need two or more slightly varied groups. For example, when we were looking to add Leaderboards for Duolingo’s desktop users, we knew that this would conflict with the existing Friends feature on desktop, since both involved comparing progress among certain sets of users. To account for this, the experiment we ran had two branches: one that kept the Friends feature in the sidebar along with Leaderboards, and one that moved the Friends feature to a user’s profile page.

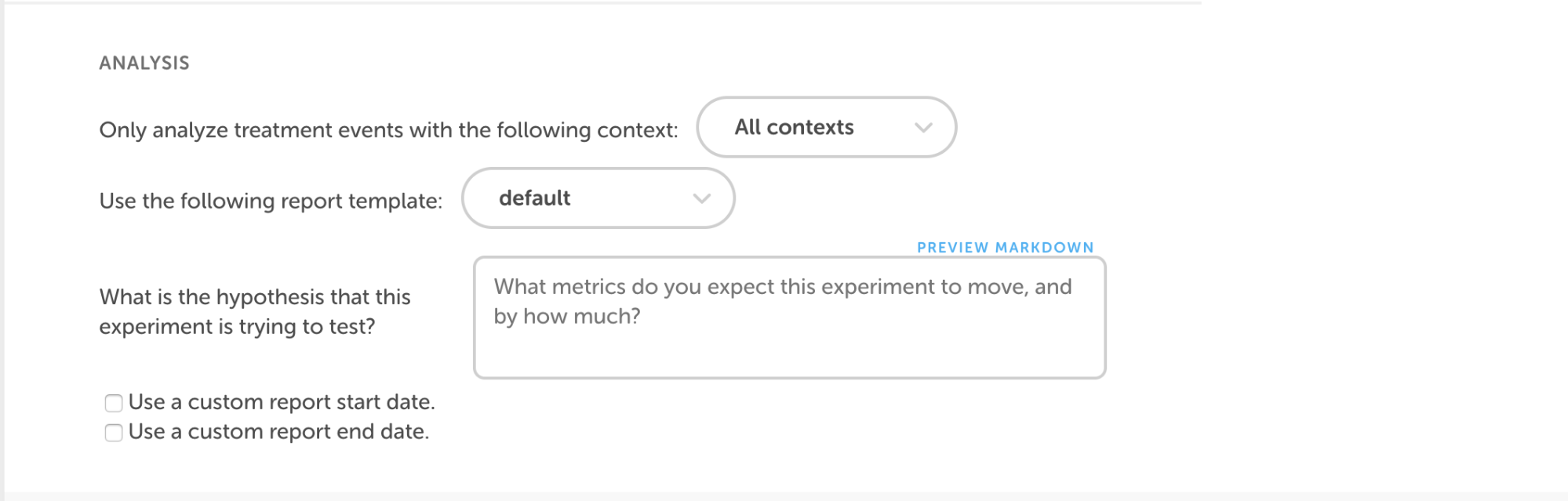
Perhaps the most important part of an experiment is identifying the results we would expect. Before running an experiment, we always come up with a hypothesis to guess what the experiment will accomplish and to establish a baseline for success or failure. The experiments service then automatically computes the analysis of the actual results, with the report template dictating which metrics are relevant to the experiment.
Once an experiment has been set up, the next hurdle is actually running it. At Duolingo, we roll out experiments gradually and carefully monitor their impact on both our platform and learner behavior. We look to the experiment analysis to indicate whether a given experiment breaks any code or hurts metrics. If we find that an experiment is broken, we pause it until the bug is fixed. If the experiment seems to be stable, we continue to increase rollout over a few days while monitoring analysis reports. Then, based on these reports, successful experiments are launched and rolled out to all users, while unsuccessful experiments are shut down.
How do we know if an experiment has succeeded?
Measuring the success of our experiments isn’t always as straightforward as it may seem. For one, not all experiments affect the same set of metrics, and including every single metric we track in every experiment report creates unnecessary clutter. The experiments service attempts to address this by defining a set of report templates, where each template contains a curated list of relevant metrics, in addition to universal metrics that are always important to consider. For example, we never want to launch experiments that negatively impact the learning experience or cause lower engagement with the app.
Every night, the experiments service generates reports for each experiment that is running, performing statistical analysis on each relevant metric to generate charts such as the following (taken from the experiment to add Leaderboards to the iOS app):
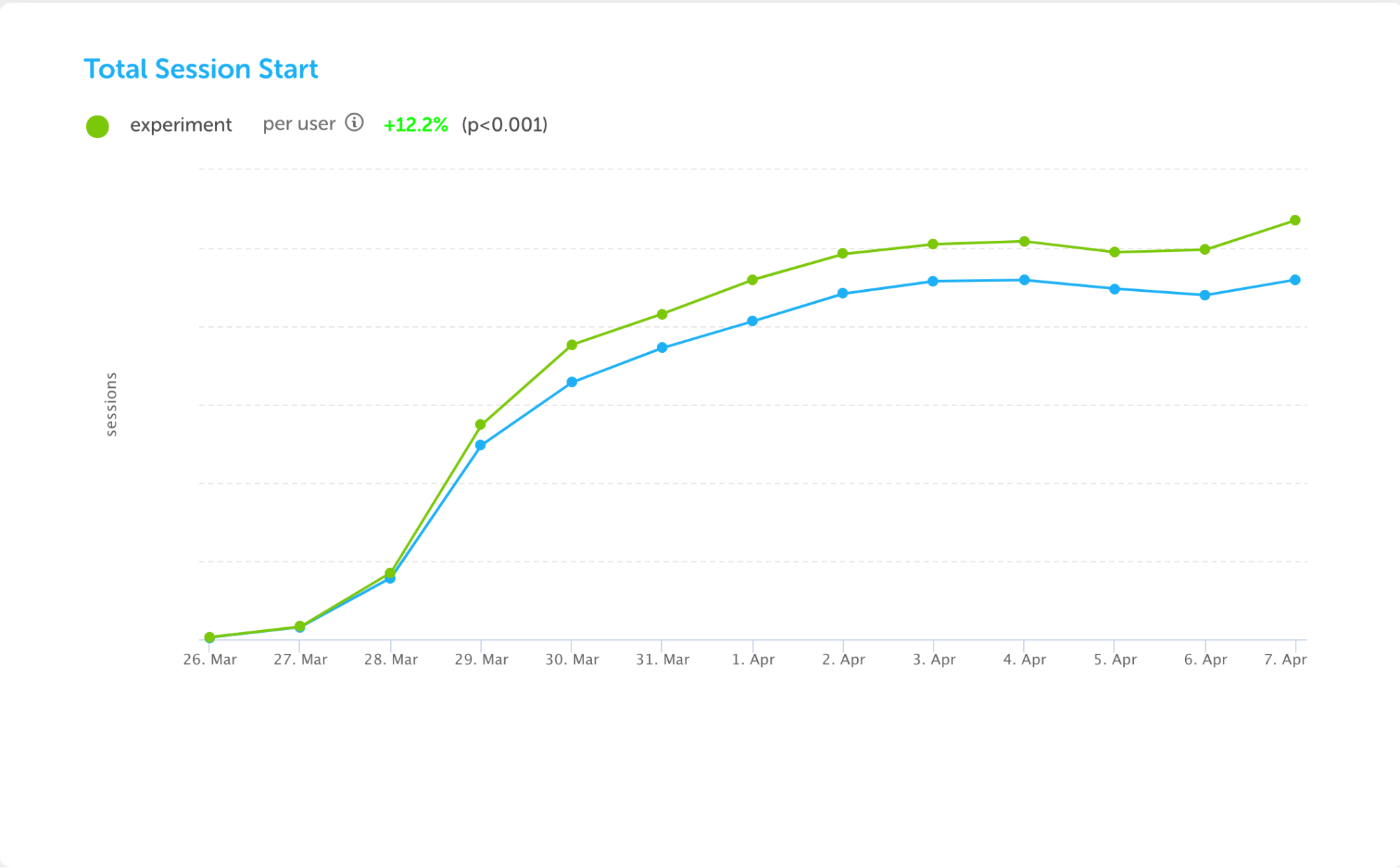
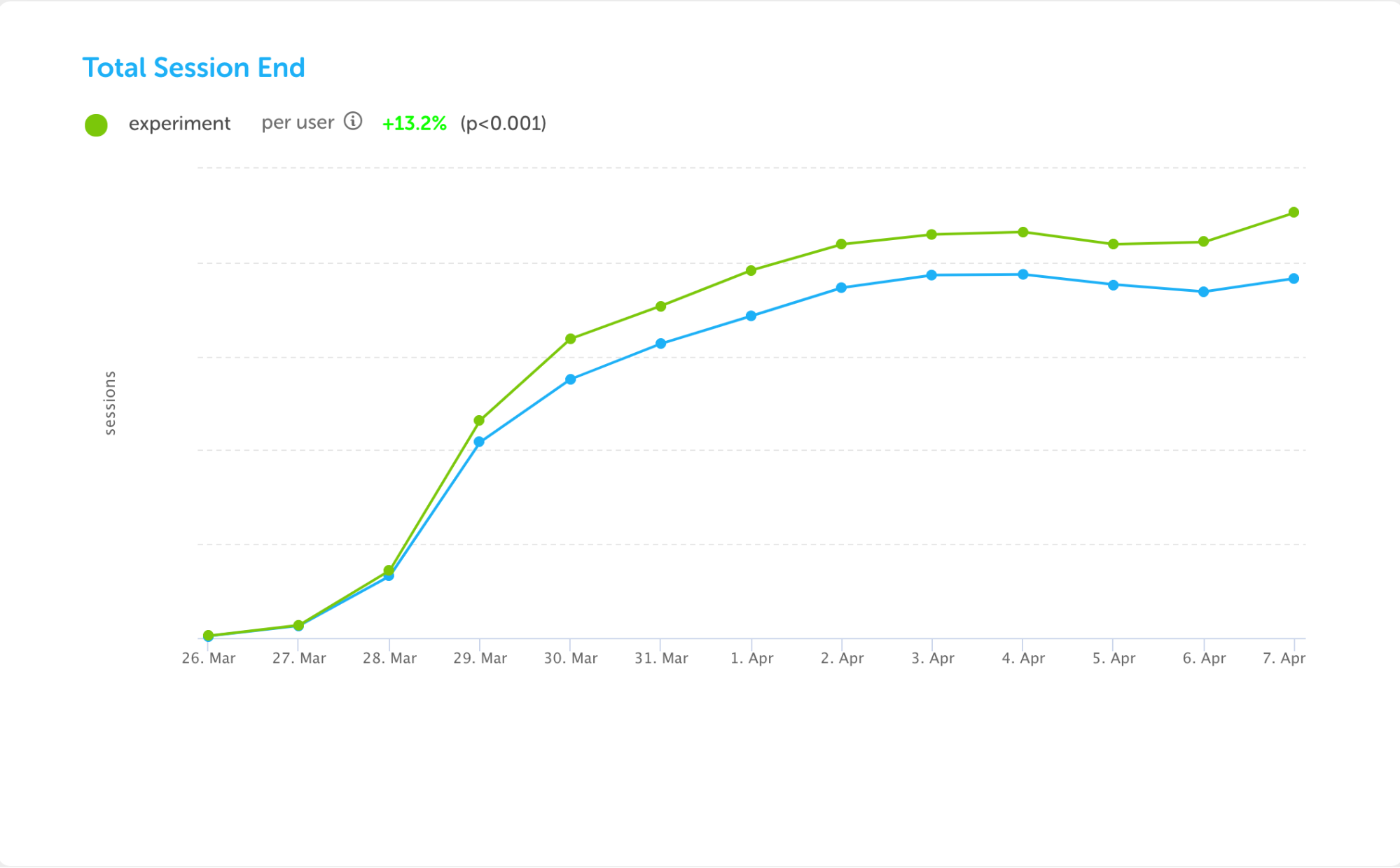
This experiment resulted not only in an increase in the number of lessons that learners started, but also in the number of lessons they completed. These metrics showed wins for both engagement and learning, which led us to launch the experiment to all users.
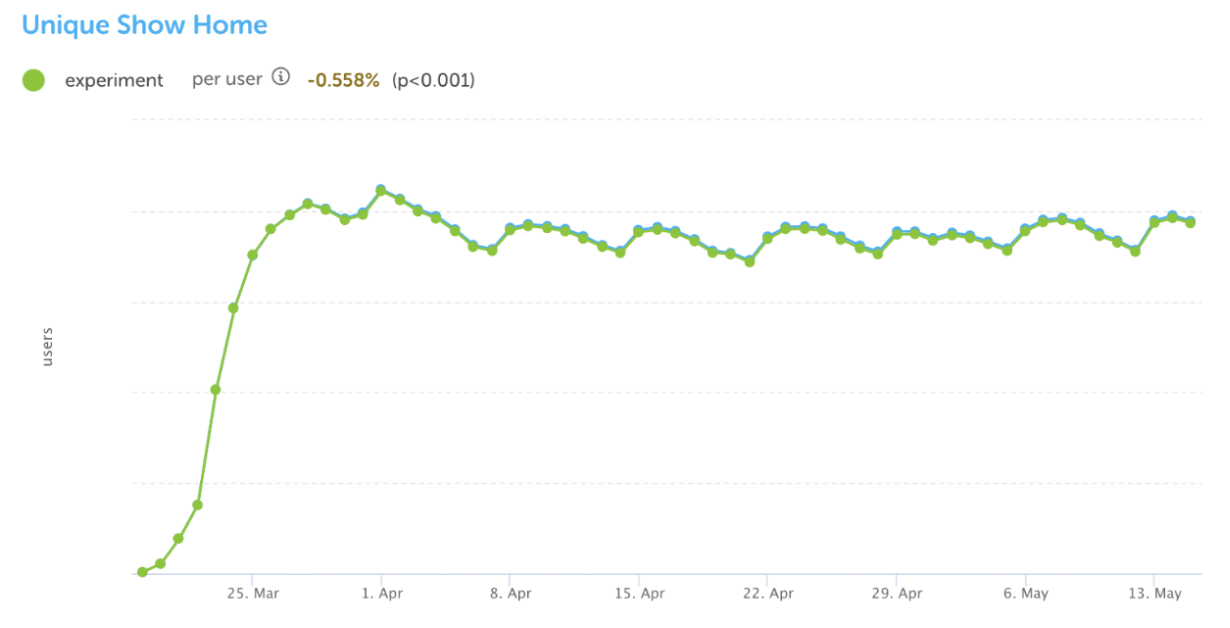
However, not all experiments turn out how we want them to. Another that we ran was related to our premium subscription, Duolingo Plus. Among other features, Duolingo Plus allows learners to download lessons to complete offline, when they’re not connected to the internet. To promote this feature, we ran an experiment that allowed users to tap on skills while offline, and they would then see an ad to purchase Duolingo Plus when they tried to start a lesson. In this case, the experiment group signed up for Plus at a much higher rate.
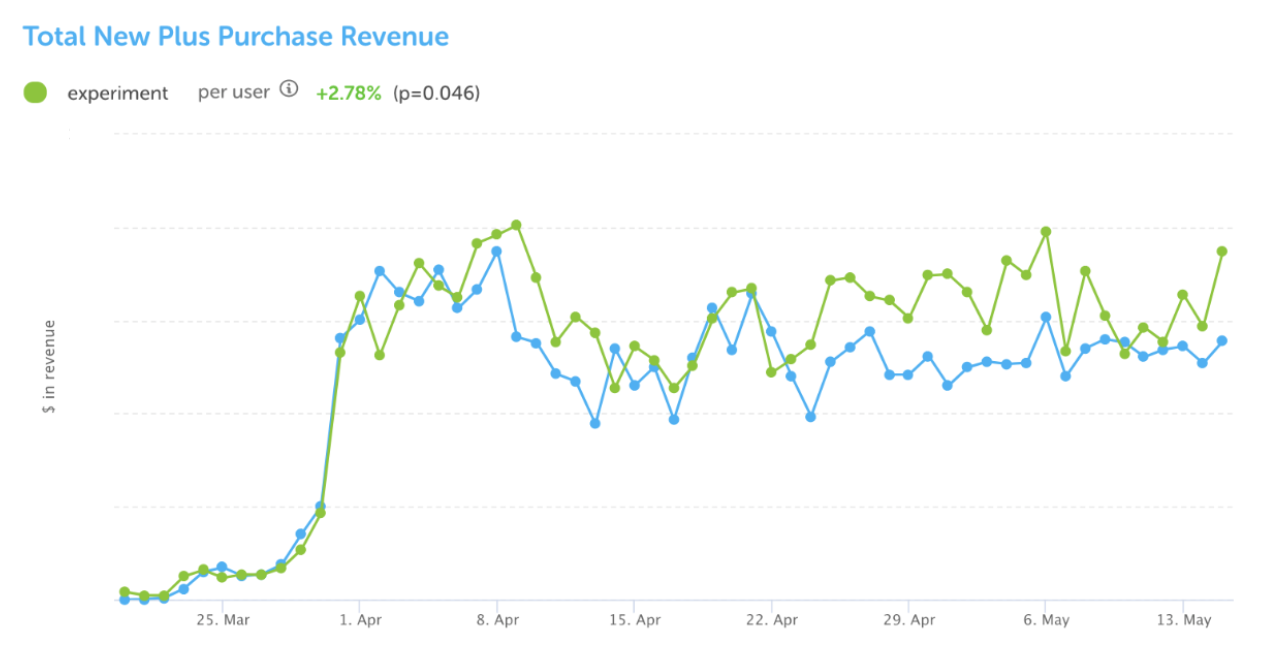
In analyzing the experiment results of the promotion, we found a double-edged sword: while there was a slight increase in revenue, we unfortunately also saw a decrease in user retention. Ultimately, because of how the promotion was presented within the app, some users in the experiment group were discouraged from using the app offline, and this resulted in a slight decrease in daily active users. We never want to launch new features that negatively impact learning habits and behavior, so even though this experiment was successful from a revenue standpoint, we decided to shut it down and iterate on it.
Our experiments service is instrumental in facilitating the process of creating, running, and analyzing experiments so that we can spend more of our time focusing on new ways to improve the Duolingo experience. Moreover, with each experiment report—regardless of whether the experiment gets launched or shut down—we learn something new about our learners and our app. This leads to more informed ideas, more informed decisions, and a product that gets better with every single release.