
Duolingo’s mission is to develop the best education in the world and to make it universally available. To fund that mission, we rely on a combination of revenue streams, including ads shown to non-subscribers. After each learning session, users either see an “in-house” ad promoting our Duolingo subscription or a “network” ad that generates ad revenue from external advertisers.
There’s significant value in serving the right ad to the right learner. But, back in 2023, our ad decision logic had become too complex to optimize effectively. Years of iterative A/B testing had led to a tangled web of decision rules, split across different parts of our codebase.
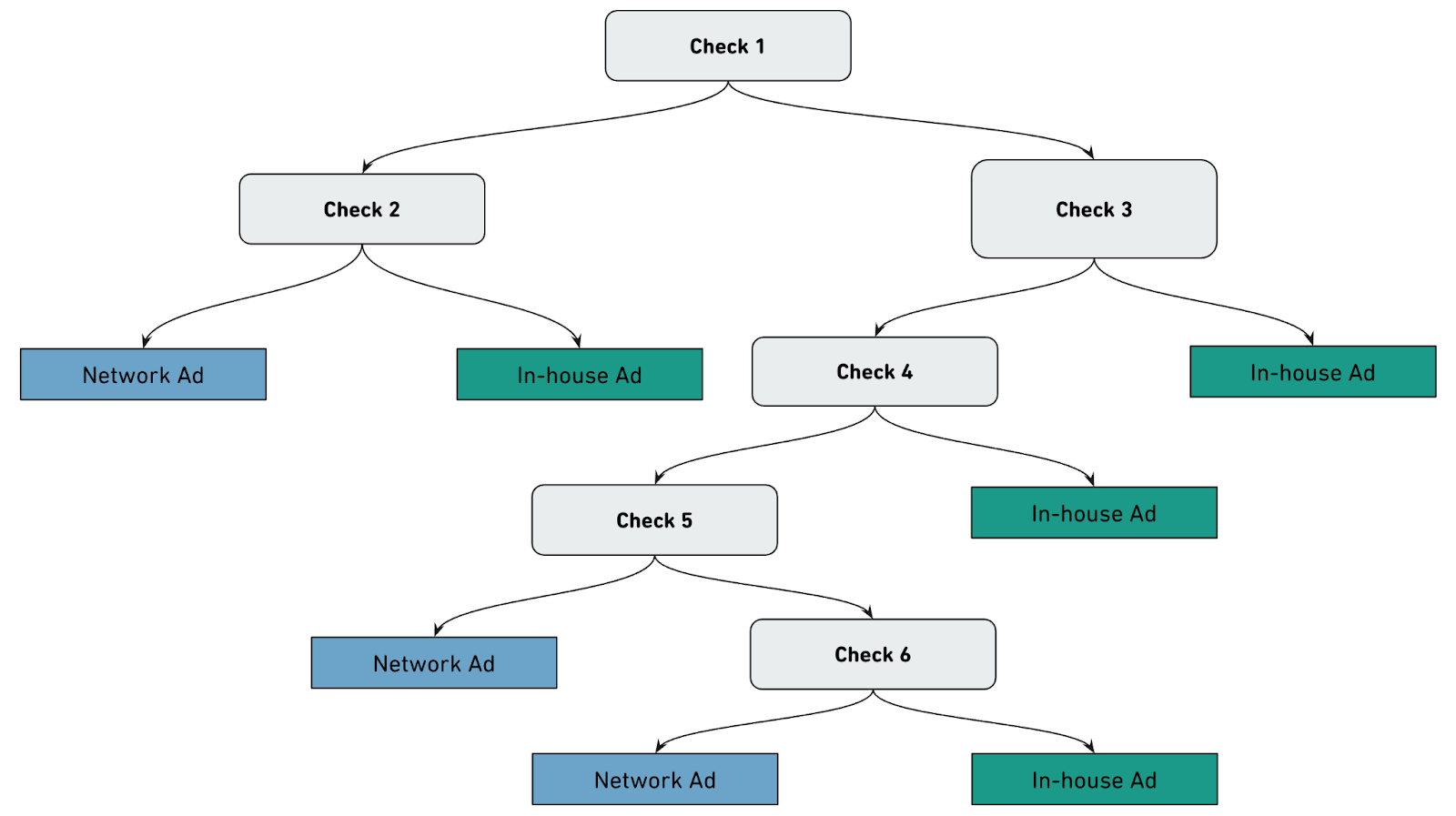
The logic was difficult to fully understand and reason about. Furthermore, fragmentation across different systems made the whole ecosystem difficult to improve and prone to bugs and tech debt.
We needed a smarter, scalable solution
We knew machine learning (ML) models could help, but our senior leadership wasn’t convinced. Duolingo is a heavy user of AI & ML, but there’s a reason our app-facing AI products are foundational efforts like Birdbrain and Duolingo Max: maintaining an ML system is a large investment, and the return needs to be high enough to justify that investment.
Our initial model would only optimize a single screen, so there was a cap on the return we could get. To get leadership buy-in, we needed to prove we could implement the solution quickly, cheaply, and with minimal new infrastructure.
Leveraging existing tools for fast deployment
Our solution? Leveraging dbt and BigQuery ML, which are seamlessly integrated thanks to the dbt_ml package. dbt already powers all of Duolingo’s data pipelines, so spinning up a new job to continuously process fresh batches of data was simple. BigQuery ML then let us use that data to train, evaluate, and analyze off-the-shelf models with just a few lines of code, all while handling hyperparameter tuning – no custom infrastructure required.
Performing inference was then as simple as running a SQL query. We got leadership approval, and after some additional engineering to store model decisions in our prod database, our implementation was ready in record time. Suddenly, a future with this logic wasn’t very far off:
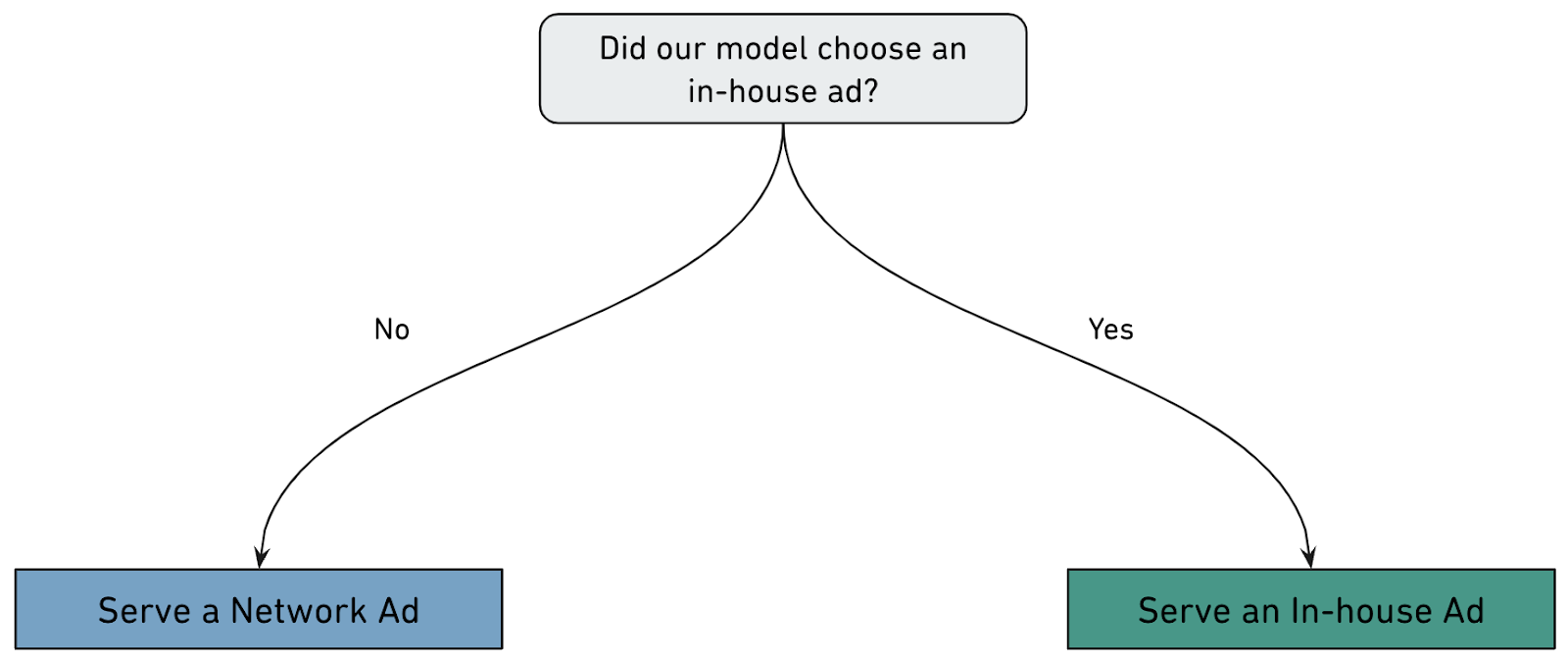
Immediate $$ gains, and growing
The impact was fast and impressive. In the first few months, the new model delivered millions of dollars in incremental annual revenue. After refining the model and fixing some pre-existing bugs, that number grew to tens of millions per year. Today, our ads decision space has become Duolingo’s largest revenue source, driving roughly a quarter of our year-over-year revenue growth.
Simplifying the system and unlocking new opportunities
The shift to ML didn’t just increase revenue, it also dramatically simplified our ads infrastructure. We were able to:
- Better personalize decisions. We could increase revenue with even more sophisticated decisions than our previous heuristics.
- Centralize logic. We could make code more modular and less prone to bugs.
- Abstract away complexity. We could eliminate repetitive forked decision logic, reducing bug risk.
Of course, we’re not stopping here, we’re constantly improving our models. For example:
- Deciding the ad type is only half the battle. Even once we’ve decided to show an in-house ad, we’ve got dozens of creatives to choose between. Using ML to decide the right creative for each learner is our next big lever.
- We’re expanding into user growth. We’re using the same infrastructure to predict, then nudge, learners who are unlikely to return the next day. This has already led to substantial daily active user (DAU) wins, but I’ll leave that for a separate blog post. ;)
Key lessons from our journey
Throughout our ML journey, we’ve learned valuable lessons that can apply to any company building ML systems for monetization:
- Avoid dedicated holdout groups. For retraining, we initially kept a learner group unaffected by our model. This introduced its own type of data drift, since we were retraining our model on fundamentally different learners than we were applying it to. Now, we occasionally ignore the model decision and serve an ad randomly, which is simpler and more effective.
- Model causal uplift. Our model initially predicted the baseline probability of a subscription purchase from an in-house ad. While this was a good start, further improving model performance didn’t increase overall revenue; it just cannibalized it from other hooks by better serving ads to learners who would have purchased anyway. Instead, we turned XGBoost into a contextual bandit by identifying learners for whom showing an in-house ad increased their purchase probability the most.
We’re excited to keep iterating and learning. Eventually, our model will get so good that it will only feel natural for you to purchase a subscription. ;)
Alternatively, you can join us! We’re hiring, and every employee gets a free subscription.