
Everyone who uses Duolingo has a different starting point of language proficiency. In order to determine a new learner’s existing skill level, we use a placement test to determine where they should begin within a course. But unlike placement exams you might have seen in college, Duolingo’s placement test is quick and efficient. We want to get you learning new material as soon as possible, and don’t want your first experience with Duolingo to feel like you’re taking a long exam. This summer I had the opportunity to work on a series of changes to the placement test to help improve how effectively Duolingo measures a learner’s language ability. This blog post will explain what the placement test is, how it works, and how we can use partial credit to make it better.
What is the placement test and how does it work?
For starters, the placement test is an adaptive test. That means after every question, your skill level is estimated, and the next question is chosen based on this new estimate. At the beginning of a placement test, it’s assumed that you’re a novice to the language, so the questions start out very simple. If you get a few questions right, we start asking tougher questions to challenge you. At the end, we consider the difficulty of the questions we asked and whether you got them right or wrong, then we unlock the skills we think you already know.
What’s wrong with the placement test?
Before I ever studied German in college, I started with Duolingo. Then after studying for a year, I wanted to keep practicing over the summer, so I wiped my progress and took a placement test. During the test, I’d translate a noun or verb incorrectly every so often, and by the end of it, I hadn’t unlocked very many skills. I started doing lessons, and they were all too easy for me. So I wiped my progress again, retook the placement test, and happened to get a lot fewer nouns/verbs that I didn’t know. Now I had unlocked many more skills, and the lessons felt much closer to the appropriate difficulty.
Where does this problem stem from? The answer is simple: the placement test counts every answer as completely correct or completely incorrect — no inbetween. Even though your sentences might have the right grammatical structure, the placement test just doesn’t cut you any slack.
How can we improve it?
What if the placement test could detect the severity of our mistakes and determine when we get questions mostly correct? This idea of incorporating mistakes into grading is exactly what we worked on improving this summer!
The good news was that we already categorize mistakes from learners whenever we grade their responses. We started experimenting on web first, because there we have the richest grading information out of all of our platforms.
Now, how do we use this information? Depending on the type of mistake, we want to assign some sort of correctness to it. For example, forgetting a noun should be considered worse than forgetting the article before it. We also want to be more lenient with our grading on certain challenge types, because a challenge where you have to translate text is harder than a challenge where you have to type what you hear. So given the mistake type and the challenge type, we tried to assign reasonable scores for how correct the answer is. Then it was just a matter of plugging these scores into the existing machinery for the placement test.
What do the changes look like?
When we had an idea of what we wanted to do, we ran simulations to see what the effects would be compared to how our placement test algorithm works currently. The simulation consisted of generating a bunch of challenges at random rows and varying the number of correct and incorrect responses. To illustrate the differences between the old grading scheme and the new grading scheme, we assigned a mistake to every incorrect response that would boost the response’s correctness.
In the graphs below, we show a sample run of the simulation. The blue bars represent the old grading scheme, the red bars represent the new grading scheme, and wherever they overlap is purple. The x-axis is the depth in the skill tree, and the y-axis is how likely we think the learner should be placed at that depth. In other words, the highest bar in the graph is our best guess at where the learner should be placed.
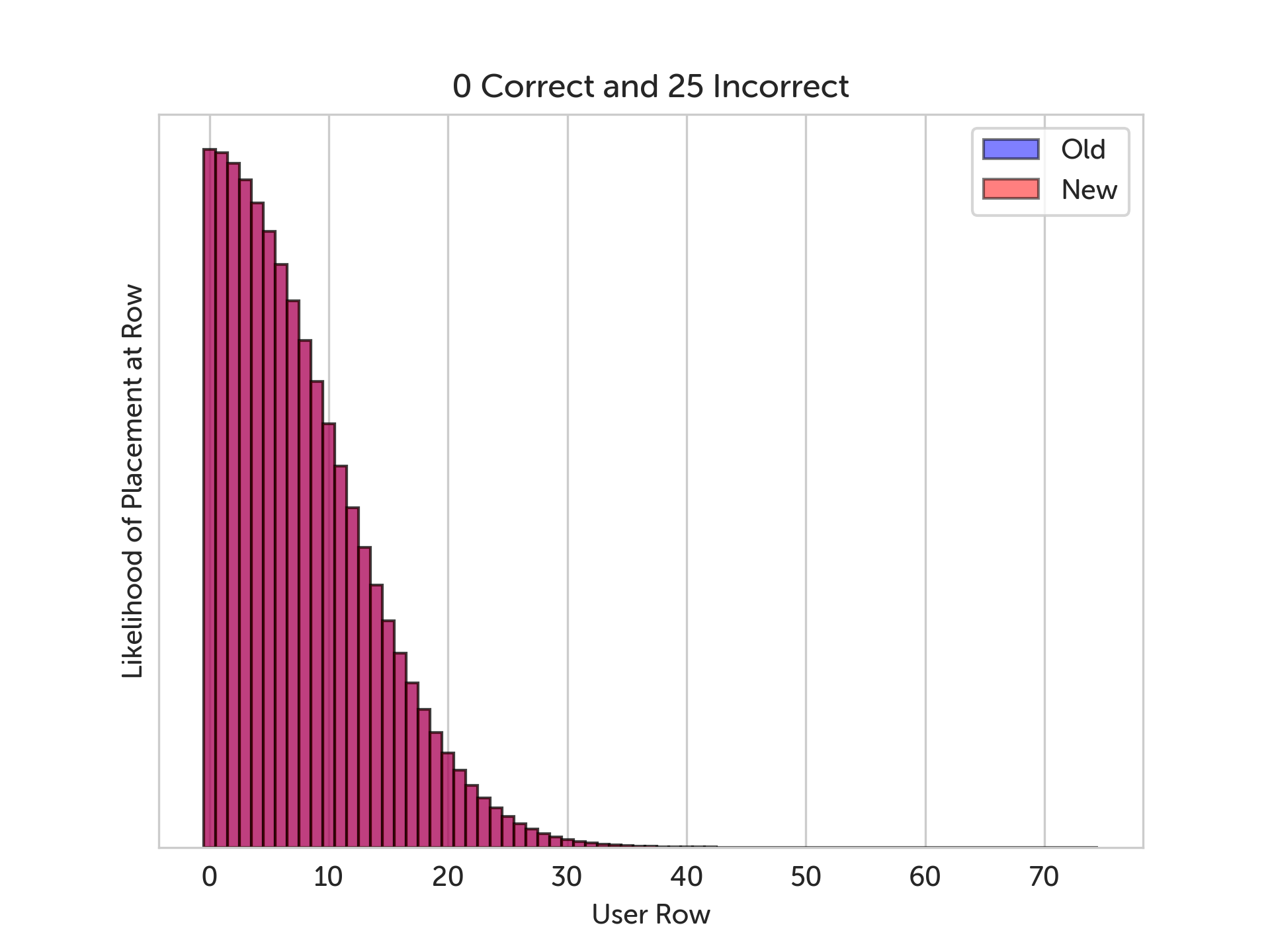
With this many incorrect answers, we can’t really see a difference between the two algorithms. But when we increase the number of correct answers, we can see the grading improvements shine.
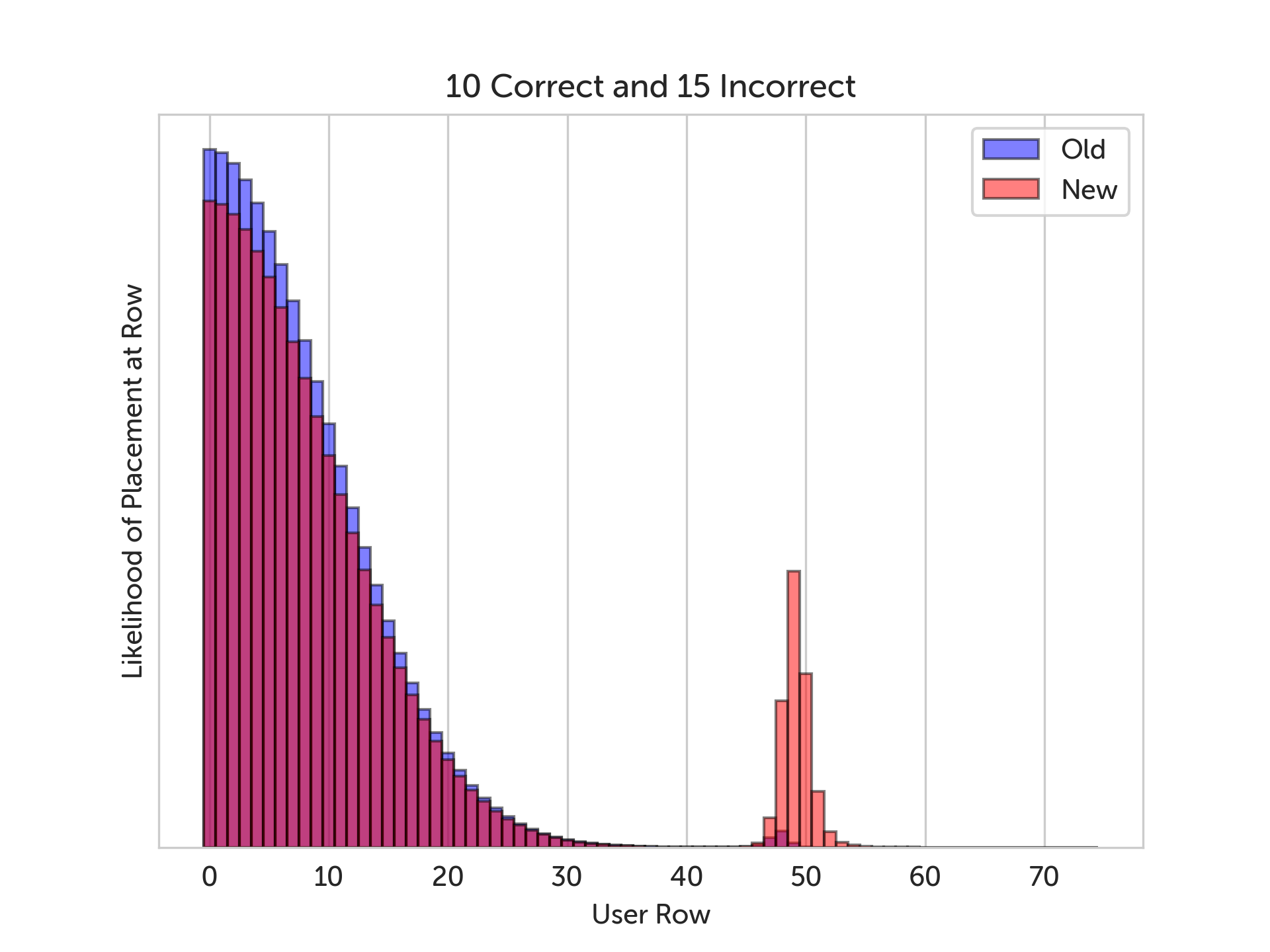
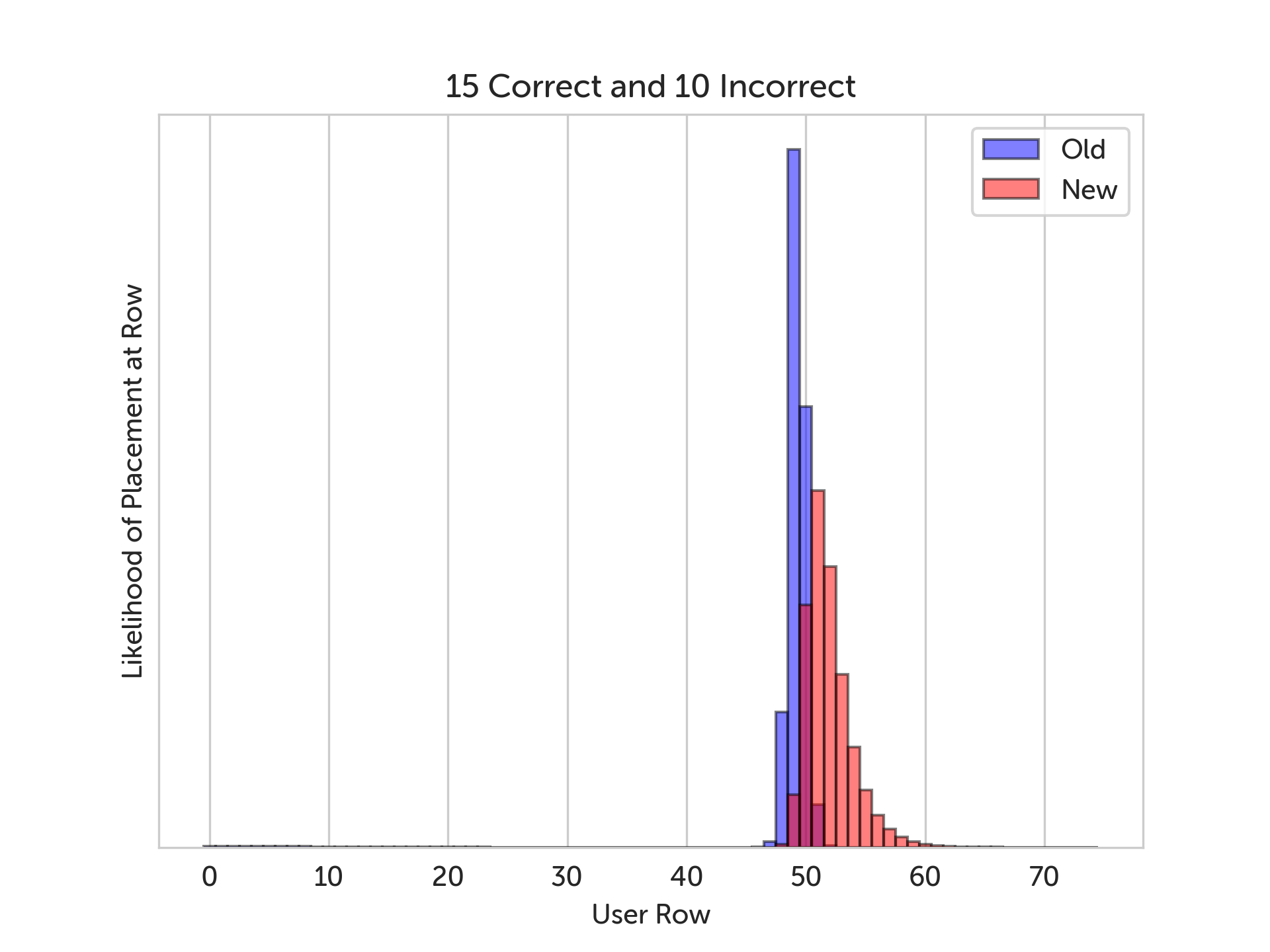
In the graphs above, we vary the number of correct answers from 10 to 15, and we can see the new grading algorithm “jump ahead” of the old one, because it’s accounting for the types of mistakes being made in the incorrect answers. Note that if the incorrect answers had no mistake category assigned to them, then we wouldn’t see any difference between the two algorithms, because then we couldn’t give any partial credit.
What’s next?
For our initial experiment, we restricted the amount of grading information we used, just to get a taste of how it could improve grading. But if we remove these restrictions, we could get a lot finer granularity on our grading and hopefully achieve even better results.
Another problem is that the correctness scores were pretty much pulled out of thin air. We chose values we thought were reasonable and just plugged them in. A better way to go about this would be calculating correctness scores from actual user data.
Until some of these problems are fixed, you probably won’t see a huge difference in grading in the meantime, but for now, the changes provide a good foundation to build off of.
Beyond the placement test, we’re excited to see how this grading scheme could be used elsewhere in the app to further personalize the learning experience. Maybe we could cook up a lesson for practicing noun genders, verb conjugations, grammatical cases, etc. — all depending on where your strengths and weaknesses lie.