
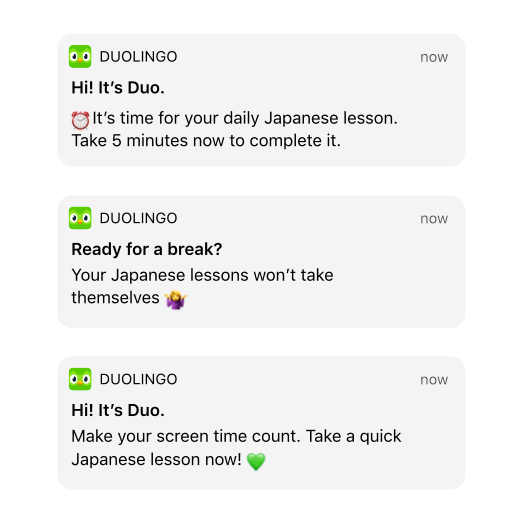
Praticar todos os dias é essencial para aprender idiomas, e por isso o Duolingo ajuda as pessoas a manter o ritmo com lembretes diários. Aliás, a persistência do Duo é tão conhecida que já virou até um meme famoso na internet. E vamos ser sinceros: a maioria de nós provavelmente já ignorou uma dessas notificações – não sem uma dose de culpa.
Entretanto, você já se perguntou como o Duo decide qual mensagem vai mandar? Ano passado os engenheiros de aprendizado de máquina do Duolingo construíram um sistema de inteligência artificial (IA) muito bacana para definir o lembrete ideal para cada pessoa em cada dia! Publicamos recentemente um artigo científico sobre esse algoritmo inédito após apresentá-lo na Knowledge Discovery and Data Mining (KDD) Conference 2020 – ou Conferência de Extração de Conhecimento e Mineração de Dados de 2020, em tradução livre. No post de hoje vamos dar uma olhadinha na IA por trás dessas célebres notificações.
Em resumo
Usamos uma série de lembretes de prática pré-redigidos, que são personalizados com base em diversos fatores, como idioma estudado e tamanho da ofensiva. Também atualizamos os textos de tempos em tempos para que eles continuem relevantes e interessantes. Como um dos princípios operacionais do Duolingo é testar tudo, sempre conduzimos experimentos para testar novas notificações com um pequeno grupo de pessoas antes de enviá-las para todo mundo. Dessa forma, apenas os melhores modelos entram para o nosso banco de lembretes.
Antigamente as notificações a serem enviadas eram escolhidas de forma aleatória nesse banco. Então nos perguntamos se tornar o algoritmo de seleção mais inteligente ajudaria a motivar mais pessoas. Será que a IA poderia achar o melhor lembrete para mandar para cada pessoa em cada dia? Assim, ano passado alguns dos nossos engenheiros de aprendizado de máquina se empenharam na construção de um sistema de IA específico para isso.
Algoritmos bandit
Para entender melhor como as pessoas respondem às diversas notificações, começamos a fazer experimentos com algoritmos do tipo bandit. Eles são uma forma de IA em que um algoritmo escolhe alguma coisa várias vezes dentro do mesmo conjunto de opções e aos poucos aprende quais as melhores, com base nas decisões anteriores – no nosso caso, quais das nossas notificações têm maior probabilidade de levar uma pessoa a praticar um idioma.
Para entender como eles funcionam, imagine que você entra num lugar cheio de caça-níqueis. Você recebe um saco cheio de fichas para jogar nessas máquinas, e algumas delas premiam mais do que outras. Para obter o máximo de retorno, você tentaria várias máquinas diferentes no começo e registraria a frequência com que cada uma dá o prêmio. Ao longo do tempo, você perceberia quais delas premiam mais e passaria a jogar mais nelas.
O nosso algoritmo bandit utiliza uma estratégia semelhante. Em vez de caça-níqueis, ele escolhe notificações, e o “prêmio” é quando a pessoa completa uma lição. Ele basicamente funciona assim:

Ciência de dados: Como descobrimos quais são os melhores modelos?
Para fazer os algoritmos bandit funcionarem para notificações, enfrentamos uma série de problemas inéditos na ciência de dados. Começamos a coletar dados, ou seja, os resultados de cerca de 200 milhões de lembretes de prática enviados ao longo de 34 dias. Nós os utilizamos para avaliar quais notificações tinham maior probabilidade de chamar atenção.
O nosso objetivo era atribuir pontos a cada uma, com base em quantas pessoas completaram uma lição após recebê-la. No entanto, um dos desafios peculiares que enfrentamos foi que diferentes notificações são elaboradas para diferentes públicos. Por exemplo, algumas delas só fazem sentido para quem fez uma aposta de ofensiva, enquanto outras só podem ser enviadas às segundas-feiras. Além disso, muitas pessoas completam lições independentemente da notificação que receberam, principalmente aquelas com ofensivas imensas, o que confere uma vantagem injusta para os lembretes voltados a esse público. Para atribuir pontos de forma justa, inventamos uma forma de comparar cada notificação somente com outras notificações enviadas para o mesmo tipo de pessoa.
Após analisá-las dessa maneira, descobrimos que não só algumas notificações funcionam melhor que outras, mas também que isso varia de acordo com o idioma aprendido. Por exemplo, a notificação “Hora de praticar [idioma]!” funciona muito bem para quem faz o curso de chinês, mas não costuma ser a melhor opção para quem faz inglês. Essas diferenças mostram que podemos cativar mais as pessoas se selecionarmos o lembrete conforme o idioma.

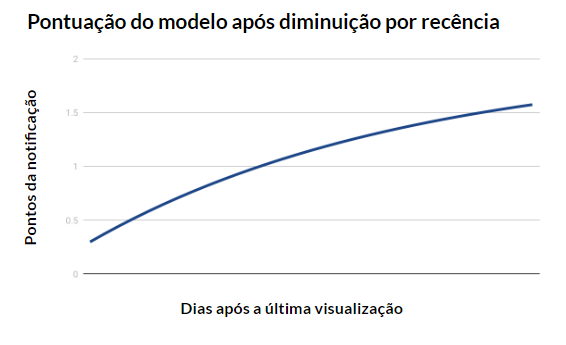
Porém, antes de poder integrar essas descobertas a um algoritmo bandit utilizável, ainda tivemos que lidar com o “efeito da novidade”. A nossa hipótese era que as notificações novas, que a pessoa nunca tivesse visto antes, surtiriam mais efeito, mas depois deixariam de ser novidade, e outro tipo de notificação seria necessário para que essa pessoa fosse convencida a continuar a prática. Conseguimos confirmar isso com a análise dos dados provenientes dos cerca de 200 milhões de lembretes que mencionamos antes. Portanto, para obter o melhor resultado, precisávamos evitar que a mesma notificação fosse utilizada com frequência.
A questão é que essa é a lógica oposta à do funcionamento dos algoritmos bandit, que encontram a melhor opção e a reutilizam várias vezes. Para corrigir isso, tivemos que ensinar claramente ao algoritmo de IA que as pessoas não gostam de ver a mesma notificação o tempo todo. A solução foi diminuir a pontuação dos lembretes que foram vistos recentemente. Decidimos o intervalo entre as repetições com base na mesma curva do esquecimento que usamos para medir o aprendizado de palavras.
Engenharia: Tem que ser rápido e potente!
Precisamos criar um bandit que fosse rápido o suficiente para processar os milhões de lembretes de prática enviados todos os dias. Ele também precisava lidar com muitos dados, pois toda semana o sistema produz dezenas de milhões de registros a serem analisados. Para aguentar tudo isso, utilizamos ferramentas de big data como AWS Kinesis Firehose e Spark.
Conclusão
Em questão de semanas após começarmos a usar o nosso algoritmo bandit no mundo real, percebemos que mais pessoas completaram lições com mais frequência. Um dos maiores feitos dele foi ajudar milhares de pessoas que tinham começado algum curso fazia pouco tempo a voltar para as lições, e sabemos que desenvolver o hábito do estudo é uma das partes mais difíceis do aprendizado de idiomas! Além disso, podemos usar as descobertas da IA para criar notificações melhores no futuro e aumentar ainda mais a motivação! Fique de olho nas informações que ainda vamos publicar sobre como escrevemos as notificações.
Se você gosta de solucionar problemas como esses, entre para o Duolingo! Dê uma olhada nas vagas de engenharia de software, ciência de dados e aprendizado de máquina na seção de carreiras do nosso site.