
Duolingo has come a long way since its humble beginnings—in just the last few years, we’ve doubled down on improving beloved features like Stories, and creating immersive lessons like DuoRadio and Adventures, just to name a few. While we’re all very excited about the future of our product, we’ve also had to face a cold, hard truth: AWS doesn’t accept good vibes as payment.
Every shiny feature demands resources to maintain, and many come with hefty price tags. Over time, these costs added up to millions of dollars a year! (We’d like to tell you the exact amount, but our lawyers said no.) And so, a grand quest was issued at the start of 2024: reduce cloud spending without compromising our product. Dozens of engineers contributed to this effort, and we raked in 20% savings (annualized) in just a few months! Here are some takeaways from that experience.
Observability is crucial
The first step was to understand where every dollar was sneaking off to. We needed easy access to data that answered, “How much are we spending, and on what?” And crucially, “How is this changing over time?”
We started with a third-party tool called CloudZero, which broke down our cloud costs into queryable line items. With this, we were able to skim through our top spenders and identify anomalies among them. There were definitely some surprises! For instance, one service’s staging resources cost more than its prod counterpart… Turns out, someone had scaled it up to test something and forgotten to scale it back down.
Increasing the number of engineers looking at costs is a great first step to saving money, so we worked on improving discoverability as well as accessibility. We improved our data coverage to include cloud services beyond AWS, such as OpenAI. We integrated cloud spending into our existing metrics ecosystem, and sent out weekly reports so teams could passively monitor their services.
The obvious: don’t pay for what you don’t need
This may sound trivial, but you’d be amazed by how many expenses we had for things we didn’t need (think about all your old subscriptions 😱). Through our investigation, we unearthed a bunch of such resources: ancient ElastiCache clusters, entire databases, and an entire microservice. Many of them belonged to legacy features whose code wasn’t fully cleaned up—but if their owners knew the literal price of their tech debt, they might’ve had second thoughts!
It’s not just about deleting unused resources, though—it can also be about deleting unnecessary data. Here are three examples:
- We had S3 buckets in active use but were also paying to preserve their entire revision history.
- We like backups, but they didn’t need to be from the dawn of time.
- We saved a lot of money by adding lifecycle rules to our largest buckets!
- We had a lot of stale data in DynamoDB tables that we were also paying to store.
- The culprit? Missing TTL rules. We added them.
- Warning: new TTL rules won't magically delete existing rows—they’re a real pain in the butt to evict!
- We were logging insanely verbose logs, without sampling, in production environments.
- Many services were overspending on CloudWatch, but we got a lot of savings by auditing their logs.
- Here’s a pro-tip for you: stack traces are huge. Don’t log them in prod.
The idea of “only paying for what you need” applies to compute resources as well! Most of our services were overprovisioned:
- A service running at low memory usage is like renting a 2-bedroom apartment and only using one of the rooms.
- The fix? Downgrade its memory allocation.
- From experimentation, we learned that almost all our services can run comfortably at 90% memory, or even 95%.
- Similarly, a service running at low CPU usage is like renting 10 trucks to move out of a small apartment.
- Here, each “truck” is a “task”—you pay for each one, so make the most of them.
- We reduced service task counts by lowering the minimum threshold and tweaking autoscaling policies to add tasks less aggressively.
- One service was so overscaled that optimizing its task allocation saved us hundreds of thousands a year!
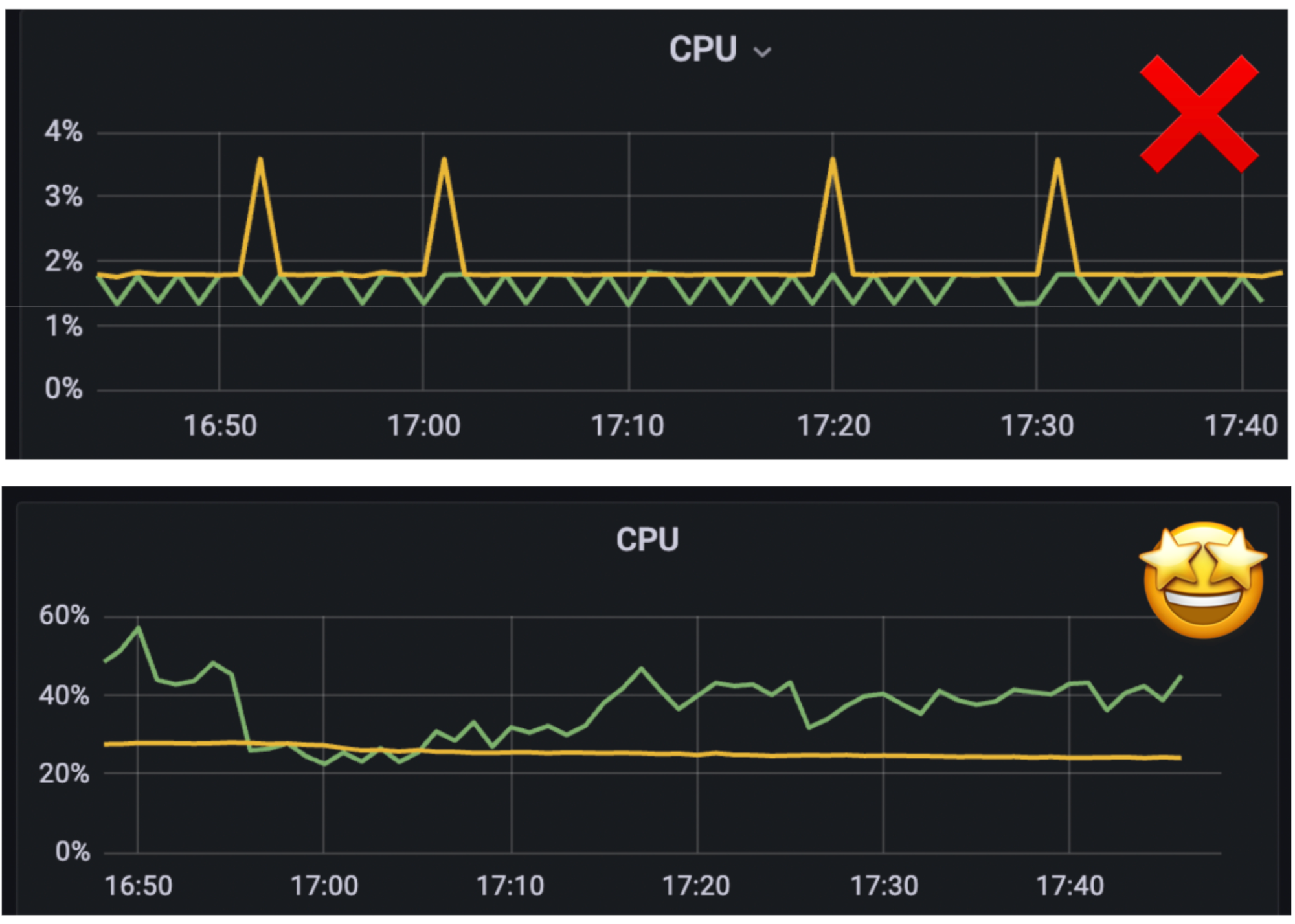
The semi-obvious: leverage built-in optimization strategies
Upon a closer inspection of the AWS documentation, we found some cost-saving policies for DynamoDB and RDS that are optimized for certain read/write usage patterns. AWS also offers autoscaling and task scheduling configurations, so you don’t have to run at full capacity 24/7 to accommodate occasional traffic spikes.
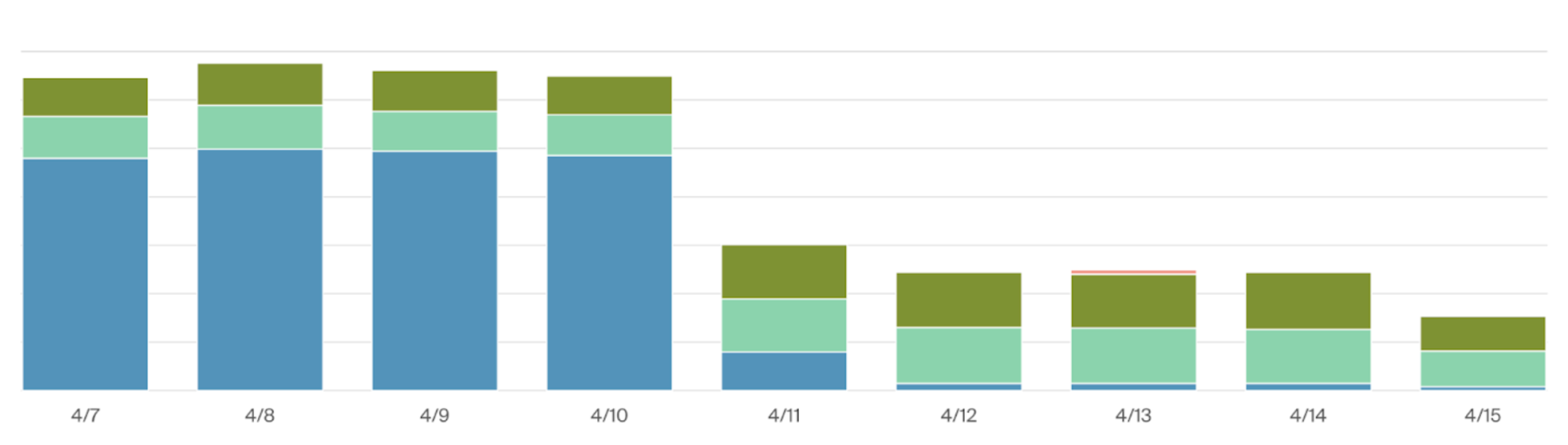
Another cost cutting solution was refining our Reserved Instances (RI) strategy. We tracked out EC2, RDS, and ElastiCache usage and allocation. It gave us visibility into our baseline of necessary compute resources, which informed our bulk purchase of compute resources through RI that we couldn't get through the Spot market.
Reduce cloud traffic
Every request in a microservice architecture can trigger a chain reaction—one service call often results in five more calls to other services. Not only does this increase load-balancing and inter-AZ bandwidth costs, it also means every service needs more tasks to handle the request volume!
Here are two ways we dealt with this:
- Refactoring inefficient code: We had a legacy service that was prone to processing indirect side effects. Some of those side effects have network dependencies, so we were making API calls willy-nilly. After the refactor, we discovered we were making unnecessary calls in the amount of 2.1 billion… per day!
- Extending cache TTLs: We had a service making constant requests for a resource that rarely changed. We upped its TTL from 1 minute to 1 hour, and it reduced traffic to the other service by >60%.
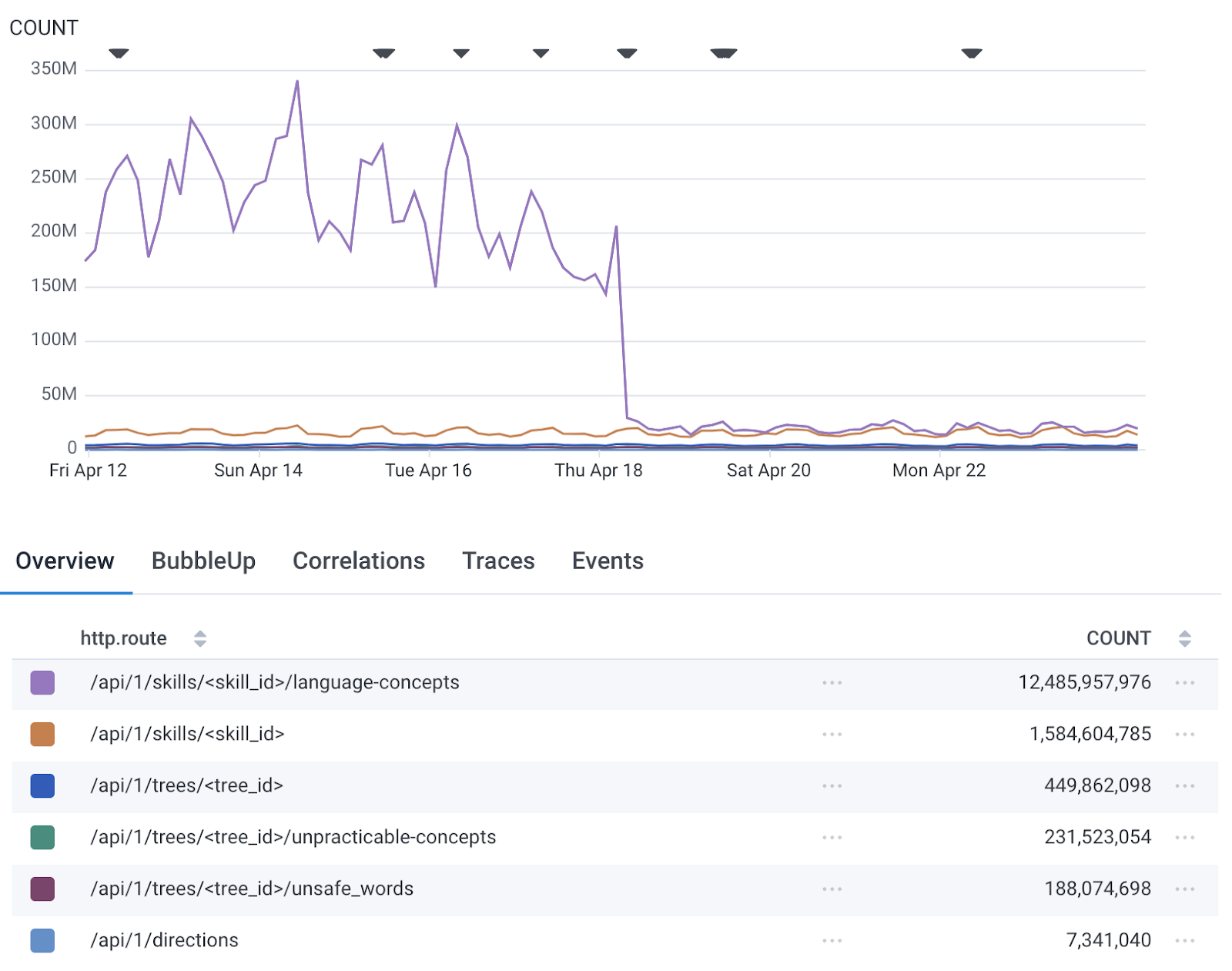
Conclusion: cost optimization and code health go hand in hand
Here’s a critical takeaway: many of our cost savings initiatives involved cleaning up tech debt and simplifying complex code. Not only did we save a lot of money, we also improved the health of our codebase! Investing in engineering excellence often results in monetary savings, and incorporating cloud costs into design decisions can incentivize you to Do The Right Thing™.
Spread this knowledge far and wide! Even if you don’t have time to commit fully to the cause, what’s arguably more important is to ingrain cloud costs into your engineering culture. Show your mentees how to find this data. Include cost estimations on your tech specs. Do quarterly reviews of your team’s spending trends and brainstorm high-ROI strategies to bring that down.
If you’re looking to work at a place that values engineering efficiency and excellency, we’re hiring engineers!