
Duolingo's fun, quirky sentences can usually be translated in many different ways. For example, the German sentence Hilfe, das Pferd frisst die heilige Kartoffel! ("Help, the horse is eating the holy potato!") currently has 72 accepted translations, with "eats" instead of "is eating", "this" and "that" instead of "the", "sacred" instead of "holy", and so on. In fact, the average number of acceptable answers to a Duolingo translation exercise is more than 200, and some longer sentences can have as many as 30,000!
Our teams work hard to try to make sure learners can put in any of these answers and be marked correct, but getting them all on the first try is close to impossible. That's why we ask for learners' help finding the ones we missed, using the "Report" flag that appears after you check your answer. Each report learners submit shows up in the Duolingo Incubator backend for our staff and contributors to review, and if they decide an answer should be accepted, they add it to the list of answers that will be marked correct.
Once a course has matured and the biggest holes have been fixed, it can become harder to find the problems that remain, as hundreds of thousands of well-meaning learners continue to send in reports without noticing they made typos or other errors. These days, about 10% of the reports we get are correct and require a fix; most of the remaining 90% contain some kind of mistake. To help our contributors find that one-tenth as quickly as possible, we built a machine learning system that makes correct reports stand out.
Words, words, words
The approach we used for this system was based on a tried and true algorithm: logistic regression. Logistic regression takes a collection of features of the report, assigns a score to every feature indicating how much the feature is characteristic of good reports, and adds up the scores to figure out how likely it is overall that the report is good. We picked features that were largely about words. Specifically, we extracted single words and two-word chunks from the learner's answer: if the report contains the two-word chunk "a apple", you can probably guess that the report is a mistake, while reports containing "colour" might be more likely to require attention from course maintainers. (We do our best to recognise every way a word might be spelt in your favourite standard variety of English!) We also compared the learner's answer to existing accepted translations and built features summarizing what kinds of changes it takes to turn the former into the latter.
Two other important considerations in building a machine learning system are the way performance is measured and the source of data to train the system. In the end, the system is used to rank reports for human review, so we chose area under the ROC curve as a way to measure how useful the system's rankings are. Finally, we got data from our report reviewing process: when staff and contributors look at a report, they mark whether they ended up accepting the suggested answer. Both accepted and rejected answers are sent to the system to teach it what to look for. (When a report is accepted, we also send a happy thank-you email to the learner who sent it.)
...But does it work for Klingon?
Many computational systems that work with human language have to be limited to a small number of languages—all too often, just one—for their initial release. However, the simple features described above are enough to allow our report prioritization system to improve using data from all of our courses simultaneously. The main reason for this is that we didn't rely on outside data or natural language processing libraries, which are often themselves limited to a few of the most widely spoken languages. In addition, most of the features refer to text in the language of the learner's answer, so training the system on a report written in English from someone learning French can later help it prioritize reports written in English from learners of (for example) Klingon.
But we don't have to wave our hands about how language-independent our system should be in theory: we can show that it works! Before our machine learning system was implemented, contributors would see reports sorted by the number of times each answer was reported, relying on the "wisdom of the crowd" to bring important problems to the top. We can compare this system for putting reports in order to our machine learning system; ranking by the number of times a report was submitted gets us an area under the ROC curve of about 0.59. A perfect score is 1, and 0.5 is what you get from a system that guesses randomly (or a sticky note on the monitor that just says "NO").
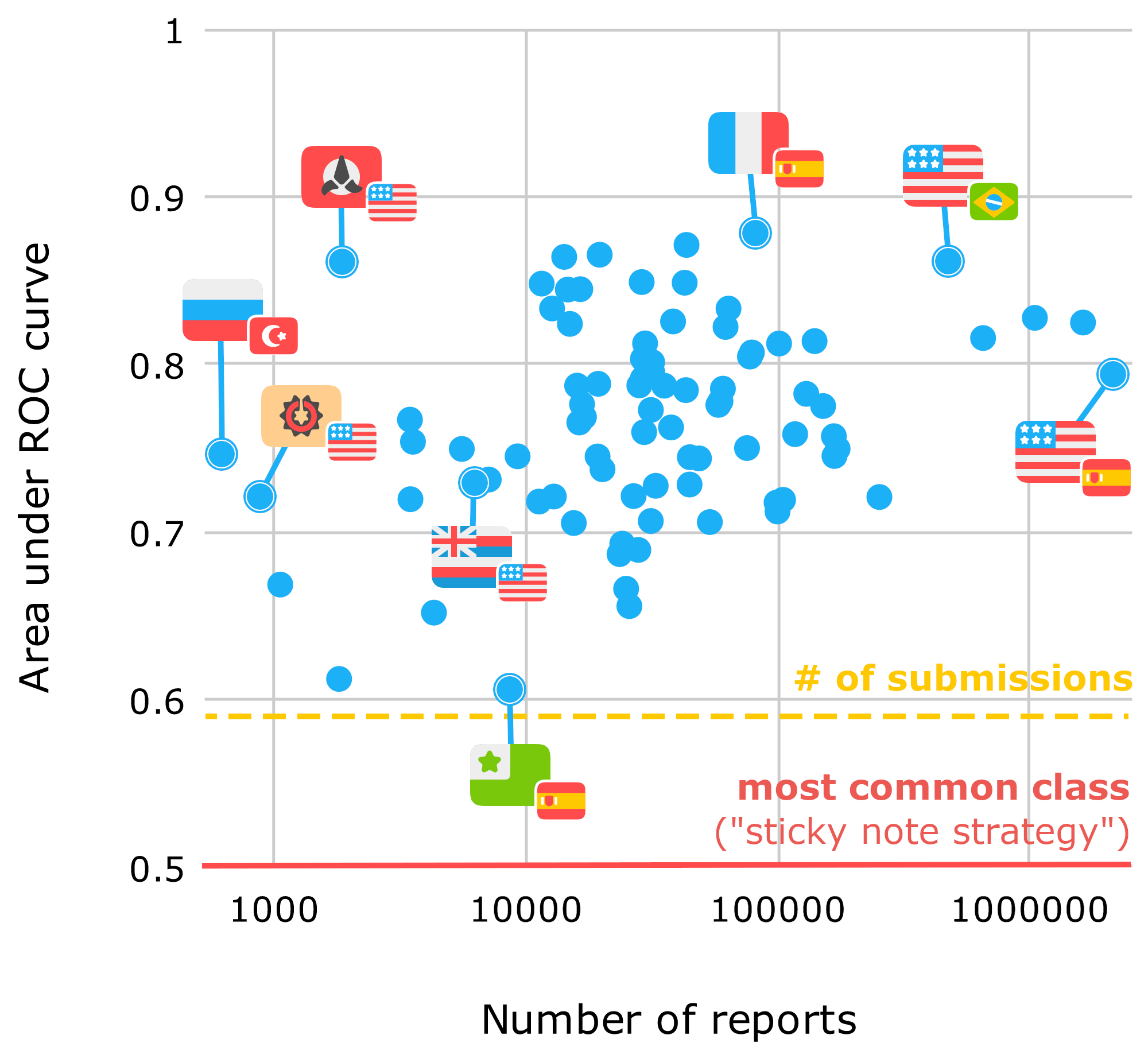
The result was a clean sweep: the new system did better than the previous strategy on every single course. Even though data was quite scarce for training the system on our Navajo and Hawaiian courses released last year, the machine learning system was still able to make useful predictions on those courses, particularly for reports in English, for which it could leverage its experience from other courses for English speakers. The Klingon and High Valyrian courses also showed surprisingly robust results.
New courses and beyond
After we implemented this system and made it available to our staff and contributors in early 2019, it has played an important role in the development of new Duolingo courses. Since we launched our Arabic and Latin courses for English speakers this past summer, contributors to those courses have been some of the heaviest users of this tool, despite the fact that the machine learning system had practically no data from these courses to start with! The Scottish Gaelic team was also among the top ten most frequent users of the tool as they tested the course prior to its release in November. Being able to address important reports quickly has made a big difference: just weeks after their release, Arabic, Latin, and Scottish Gaelic were already achieving the low rates of problem reports we expect of our most stable courses.
The design we chose for the machine learning system, in addition to being highly multilingual with only small amounts of data, was easy to implement, fairly easy to understand, and computationally very cheap. Nevertheless, it's likely that in the future we'll revisit this design and experiment with more modern language understanding techniques; the recent explosion in the use of multilingual contextual word embeddings beckons with promises of much higher accuracy and the ability to handle (most) new languages automatically. In the meantime, keep sending in those reports!