
All content that you come across on Duolingo—from the sentences in a lesson to the narrative of a Duolingo Story—goes through several iterations of scaffolding, writing, translation, and then review by different language professionals. In other words, we make sure to serve you expertly-crafted exercises that maximize your learning!
But, since courses are made up of literally millions of pieces of content (including sentences, translations, hints, audio, images… the list goes on!) no amount of testing and review will ever leave a course completely error-free. We have a really efficient system for managing user reports, but we’re getting 200,000 reports per day! How do we sift through them all? We’re glad you asked!
TL;DR: how learners provide feedback
We provide every learner with the ability to submit a report. This part is simple: after checking your answer in an exercise, you can hit the "Report" flag that appears next to the solution.
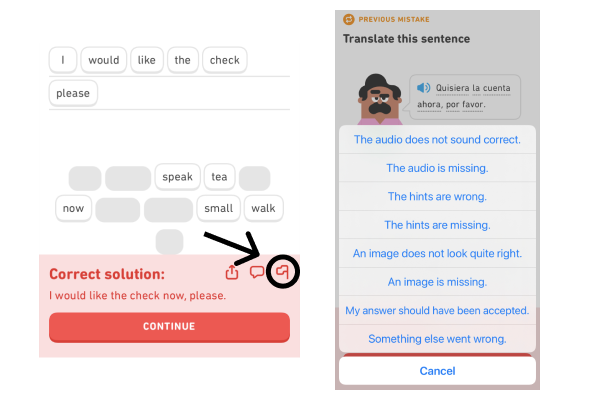
Depending on the type of exercise and whether your answer was graded as correct or incorrect, we’ll show you a menu of different error types that you’re able to report. This means that every different exercise has a different menu of possible issues that could arise, and it’s our way of providing you with opportunities to send us feedback!
But how do we address 200,000 reports every single day?!
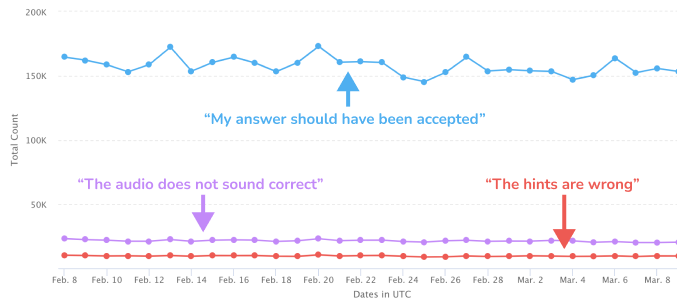
Cumulatively across all error types, Duolingo receives around 200,000 user reports from learners everyday. The three most-selected error types are:
- “My answer should have been accepted” (72% of all reports, on average)
- “The audio does not sound correct” (10% of all reports, on average)
- “The hints are wrong or missing” (5% of all reports, on average)
But with thousands of new reports being received everyday (and only so many people who can review them), how do we decide which reports get reviewed? And how do we ensure that the highest quality reports—reports that we think are pointing out a real issue—are prioritized?
Where machine learning and language learning collide
In our quest to provide the highest quality language-learning content, we’ve built out dedicated tools and machine learning models to help our teams prioritize, review, and resolve each type of report at scale. One of our most useful tools helps us to triage the thousands of reports that fall under…
“My answer should have been accepted”
You might be wondering why the majority of user reports are of this type. But, think about it:
On Duolingo, the Spanish sentence, No necesito un taxi, vivo cerca (I don't need a taxi, I live close by) has a whopping 2,156 acceptable English translations! This is a result of the different versions of acceptable word orders (As I live close by, I don’t need a taxi), contractions (I don’t vs. I do not), and synonyms (nearby vs. close by). In fact, depending on the sentence length and language, a single sentence on Duolingo can have upwards of 200,000 acceptable translations!
With this in mind, it’s reasonable to expect that we missed a few acceptable translations, and we’re always interested in adding valid learner-suggested translations. That’s why we built out a machine learning model to help us identify reported answers with the highest likelihood of being valid translations.
The model, known as the Report Quality Estimation Tool, takes into account all sorts of things (the user who submitted the answer, how many other people have reported the same answer, and how different the answer is from known acceptable translations) to produce a ‘report quality score’ that we use to prioritize which reports are reviewed first.
Reports also help us measure our teaching
User reports are really helpful at quickly finding and fixing content errors for thousands of learners. But an equally (if not more) important application of user reports is to see how well learners are grasping specific language concepts.
Here’s one way we analyze our bug reports: of the tens of thousands of “My answer should have been accepted” reports that we review each day, only about 15% of them are actually deemed ‘correct’ and end up as a new accepted translation. But think about the learner who took the time to file the report and attempt to submit a new translation. They must be pretty convinced their answer is right! This type of report can be a strong signal of concepts our learners aren't understanding clearly, and therefore that we could potentially teach better.
That’s why we provide our course creators with insights into the number of reports per session on the course, section, skill, and even exercise level. These insights enable our language content creators to pinpoint grammatical structures and vocabulary that may need a different teaching method or prioritize certain sections for Smart Tips.
Keep those reports coming!
It’s when delving into topics like these that I appreciate just how impactful it is to have an active community of learners that care and contribute. I hope I’ve made it clear just how much value we garner from user reports and in turn how this improves the learning experience for our users. So, thank you to each and every one of you for (responsibly) letting us know when we’ve missed something. You keep us on our toes and help others learn more effectively.