
この1年の間に、Chat GPTのような大規模言語モデル(LLM)によるAIと「会話」してみた方は、きっと多いことでしょう。この種のAIは、記事の要約から挨拶状の作成、さらには旅行プランの提案まで、色々なことに活用できる可能性を持っています。一見したところ魔法のように見えるかもしれませんが、その正体は、あなたが出した指示(プロンプト)に基づいて文章を生成するという機能にあります。この指示が適切であればあるほど、AIからの応答も、より具体的で的確なものとなります。
「ひょっとしてこれは、外国語での会話の練習に使えるかも...?」と感じた皆さんは鋭い!とはいえ、単に「私とスペイン語を話す練習をしてください」と指示するだけでは、狙い通りの、あるいはパーソナライズされた学習体験は得られないかもしれません。もちろん、型通りの受け答えでもある程度は役に立つでしょう。でも、AIモデルを最適化して、会話しながら語学を教えてくれるようにできないのでしょうか?
Duolingoでは、以前からこの課題への答えを探し、ロールプレイ機能の開発に取り組んできました。そしてついに、これを実現しました!この機能を開発するためにLLMに与えた指示は、「私とスペイン語を話す練習をしてください」というような単純なコマンドではありません。エンジニア、デザイナー、言語学者、プロダクトマネージャーからなるチームが工夫に工夫を重ねて開発した、複雑なプロンプトのシステムです。ロールプレイ機能の目標は、ターゲットを絞った、楽しく、効果的な言語学習体験を提供することです。AIの魔法を利用したこの機能では、ユーザーとの会話を自由自在に操る裏で、常に言語スキルを向上させるような仕組みが働いています。
この機能がどのように機能し、言語学習の旅にどのような革命をもたらすのか、さらに深く掘り下げてみましょう。
ロールプレイ機能の仕組み
LLMモデルはプロンプトと呼ばれる一連の指示に基づいて動作します。Duolingoのロールプレイセッションでは、ユーザーはおなじみのDuolingoキャラクターの一人と会話を交わしていきますが、この会話を導いているプロンプトをちょっと想像してみましょう。たとえば「あなたの名前はオスカーです。スペイン語を学んでいる人と話しています。今から週末の予定を相談するところだと想定してください。」するとLLMモデルが作動し、あなたと臨機応変に会話し始める...
…と言いたいところですが、そんなに単純なものではありません!実際には、オスカーがあなたの会話に反応するたびに、毎回違ったプロンプトが作動し、彼の発言をコントロールしており、これらのプロンプトの一つひとつは、オスカーに特定の反応を起こさせるように作られています。例えば、あなたの発言に対し質問を返させるプロンプト、逆にあなたが思わず質問したくなるような発言をさせるプロンプト、話題を変えるよう誘導したり、会話を終わらせたりするために最適化されたプロンプトなどです。
もっと分かりやすいように、これを電話での会話に例えてみましょう。ロールプレイは、1対1の会話よりもむしろ、コールセンターとの通話に似ています。そう、あなたが説明したり質問に答えたりするたびに別の部署の担当者に転送されていく、あの仕組みです。
まず最初の担当者が挨拶し、質問をします。あなたが答えると、別の担当者に転送されます。この担当者は、あなたの話す内容に対し適切な回答ができるよう、専門的に訓練されています。このプロセスが繰り返され、どの担当者も、会話中にふさわしい受け答えをする能力を備えています。
ここで、コールセンターの担当者が全員オスカーの姿をしていると想像してみてください。あるオスカーが別のオスカーに会話を転送するたびに、これまでの会話の記録を渡し、引継ぎを行います。こうすることで、今あなたが話しているオスカーは会話の文脈を把握し、適切なタイミングで、質問が専門のオスカー、話題変更が専門のオスカー、まとめが専門のオスカーにバトンタッチしてくれるのです。
どのオスカーがどのタイミングで会話を引き継ぐかは、入り組んだフローチャートのような 「ルール」があると考えてください。たとえば、オスカー①はナレーターが何かを言った後にだけ発言でき、オスカー②はあなたが返答した後にだけ、オスカー③は何度かやりとりした後にだけ発言できる、といった具合です。このルールのおかげで、毎回スムーズで、飽きさせず、勉強になる会話ができるのです。
学習にはどう役立つの?
一人ひとりのオスカー(つまりプロンプト)は、状況に合った自然な反応を提供するよう訓練されているだけでなく、皆さんの学習体験が効果的かつ魅力的なものになるよう、「全員」が次のような訓練も受けています。
1. シナリオの工夫
すべてのプロンプトには、シーンを設定するシナリオが含まれています。このシナリオには、背景、キャラクターの役割、キャラクターが何をしたいのか、そして学習者のCEFRレベルに合った学習目標が含まれています。これらの情報をもとに各体験のゴールが設定され、学習中の言語を使う必要のあるリアルな状況が演出されるのです。これは決してくだらない雑談ではなく、シナリオをもとに会話を特定の目的へと誘導するようにできています(もっとも、会話の主導権はあなたにあることも忘れないでくださいね)。以下はプロンプトの一例です。
学習目標: 依頼を断る
シナリオ:
- 学習者とオスカーは友人であり、学習者はオスカーの誘いを丁重に断っている。
- オスカーは学習者に、自分の甘えん坊なペットの相手をしてほしいと言い、学習者はオスカーの依頼を丁重に断っている。
2. 学習者のCEFRレベルとの一致
ロールプレイを使う学習者のレベルは、さまざまです。キャラクターが難しすぎる言葉を使うことで学習意欲を削いだり、混乱させてしまったりすることがないよう、各学習者に合った「ほどほどの難しさ」となるように調整します。一方、簡単すぎてもNGです。キャラクターが既に知っている単語ばかり使うと、あまり勉強にならないからです。ロールプレイのどのプロンプトにも、あなたのCEFRレベルに関する情報が含まれており、「発達の最近接領域(Zone of Proximal Development)」を狙った難易度が維持されるようになっています。
A1 CEFRレベルの言葉づかいを使用すること。
指示:
- 初級のA1レベルの言葉づかいのみを使用すること
- 単純な文法構造のみを使用すること
- 現在形のみを使用すること
- 単純であっても、A1レベルの言葉づかいは自然に聞こえ、文法的にも正しくなければならない。
3. キャラクターの性格
どのプロンプトも、話し相手となるDuolingoのキャラクターがどのような口調で話すかという情報を、LLMモデルに提供します。例えば、ロールプレイ中にリリーが快活に話したり、エディが元気なく声を落としたりすることはありません。私たちは、キャラクターの一般的な性格、話し方、背景の情報、他のキャラクターとの関係などの情報をモデルに与えています。これによりアプリのイメージ通りの楽しい体験ができるだけでなく、学習中の言語でさまざまな「人」と話す練習の機会が得られます。
キャラクター オスカー
キャラクター情報:
- 芸術・お洒落なレストラン・文化に情熱を注ぐ、40代の男性。
- 彼の話し方には、多少、尊大で気取ったところがある。
- 彼は自分の外見、特に口ひげが自慢である。
- 彼は演劇の愛好家である。
4. ナレーションの役割
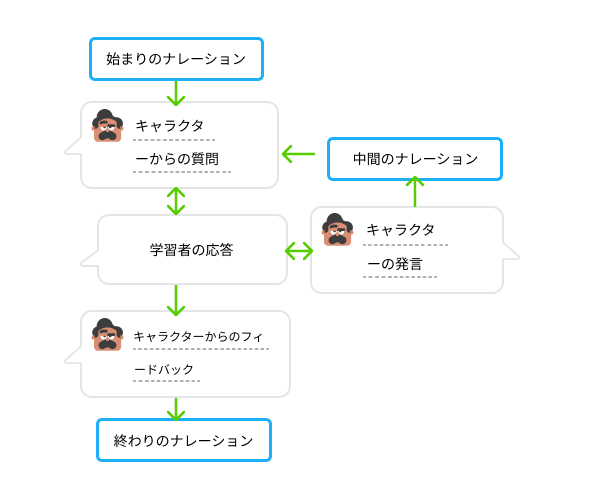
ちなみに、ロールプレイの登場人物はあなたとキャラクターだけではありません。対話の設定と締めを行い、セッションの途中で新たな情報を付け加える「ナレーター」も会話に参加します。ナレーターの役割は、場面を設定し、目標を決め、会話を現在の目標に引き戻し、最後に会話をうまくまとめることです。会話の始まり、中間、終わりにナレーションを入れることによって会話に方向性を与え、あちこち話が飛ばないようにします。ナレーションは会話の展開をコントロールし、体験を短時間で意義あるものにし、一層の楽しさを追加してくれるものです。
以下は、あなたがナレーターを演じながら台詞を始める際の指示である。
- 導入部は、シナリオで述べられている場面を設定するものでなければならない。
- 導入部では、学習者が学習目標を達成できるような対話を確立しなければならない。
- 導入部は、そのキャラクターの個性にふさわしい方法で紹介しなければならない。
結局、チャットGPTは学習に役立つの?
一般的な大規模ランゲージモデルを使って学習中の言語を練習することは可能です。しかし、自分の語学レベルに合わせて調整され、現実世界の会話のような感覚で、自分のお気に入りのキャラクターと交流しながら、短時間に集中して充実した体験をしたいのであれば、いくつものプロンプトを駆使してカスタマイズする必要があります。
そこで私たちの出番です。Duolingoでは、皆さんの言語学習体験をより楽しく、よりきめ細かにパーソナライズされ、更にはより効果的なものにするために、常にAIを調整しています。プロンプトやシナリオも既に揃っています。あとは学習者の皆さんの参加を待つのみ!ぜひ今日からこの機能を利用し、キャラクターたちと楽しいおしゃべりを楽しんでください。お待ちしています!
*ここでご紹介したプロンプトやロジックは、Duolingoアプリで使われているものを簡易化したものであり、実物とは異なります。