We have an incredibly important mission—to develop the best education in the world and make it universally available--and naturally, this requires quite a bit of technical know-how to make that happen! Our innovative culture naturally leads to technical problems that no other company has encountered, and that's where we look to our engineers to tinker around, experiment, test things out to figure out a good solution. Once we get to a solution, there is, in a way, a double reward—we improve our product and we collectively get closer to achieving our mission.

The projects below showcase a few of our unique engineering challenges, our approach to solving, and the impact these solutions have on our millions of learners. If these types of technical problems are interesting to you, we’ve got open roles for engineers and data scientists in Pittsburgh, New York, Seattle, and Beijing!
Question 1: How do we ensure all of our learners have an equally high-quality experience?
Problem: Emerging markets rely on cheaper, less performant devices, and many learners in these markets also deal with unreliable internet access. For these learners, simply using the app can be a frustrating experience: screens can be slow to load and the app may freeze entirely.
Solution: Leverage system traces to identify and prioritize key performance bottlenecks.
This year, we’ve doubled down on improving app performance, particularly on Android (which represents a large portion of our learners). We worked with our Data Science team to identify the most impactful areas to address, and decided to start with improving app startup—or the flow from tapping on the Duolingo app on your phone to actually seeing our home screen load.
System traces have been invaluable for our work. We’ve spent countless hours manually profiling our app startup code on Perfetto, breaking down the flow into a handful of key steps, and identifying the top bottlenecks to speed up.
But collaboration is also vital: we wouldn’t have been able to move so quickly if we weren’t constantly looking at traces together and brainstorming ideas. To make that easier, we created a MethodTrace tool that made our traces much easier to annotate and interpret, helping increase experiment velocity.
Using system traces, we’ve identified and addressed multiple bottlenecks to speed up startup. Many of our initial successes involved delaying work—for example, prefetching lessons for offline usage, initializing our ads SDK, or creating UI elements not immediately shown—to happen after the home screen is loaded.
We’re working on a larger project in this vein too. Currently, if it’s not already cached, we request and parse your entire course metadata on app startup. Instead, we’re in the process of only fetching data for the section of the course you’re in right now, i.e. what’s represented by the part of the learning path on your home screen. For our most comprehensive courses like French or Spanish from English, this will be up to a 90% reduction in metadata required!
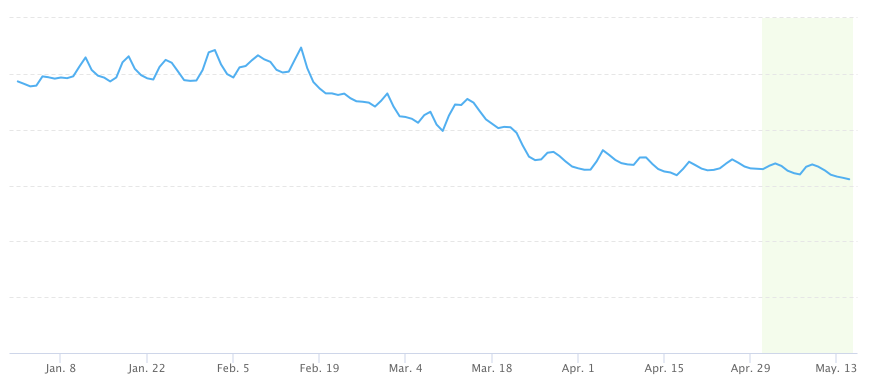
Impact: We’ve already seen great results: Android app startup time is now 40% faster since the beginning of the year! Now learners on older Android devices can successfully open the app and complete their language lessons with a lot more ease and a lot less frustration.
Question 2: How do we scale personalization for learners?
Problem: Personalizing practice for our learners requires a huge amount of A/B testing for every new ML model. How can we do this at scale?
Birdbrain is Duolingo’s system for personalizing practice for our learners. Every time one of our learners completes a lesson, Birdbrain ingests the outcome of every individual exercise (or “challenge response”) and uses an in-house ML model to estimate that person’s proficiency with different grammar concepts. We use this data to build more personalized practice sessions for learners.
At Duolingo we believe in testing everything. The only way we can really understand the impact that a new model will have on language learning is to A/B test against a large number of users. In order to effectively assess the impact of the new models on learning, we need to process every challenge response once per model we’re evaluating – effectively doubling the work we were doing before!
Once this system launched, we needed to deliver significant performance improvements to unlock model A/B testing while managing storage costs.
Solution: Write less frequently.
The scores for each course a learner is enrolled in is stored as a single row in Dynamo to minimize our API latency. The way we have this architected would imply a 2x increase in storage costs if we A/B tested both of our models at once. We decreased our baseline cost in a few ways, but the primary one was by writing less frequently.

Since the input streams to our service are sharded by “userId,” we could guarantee that the same thread will always see every record for a specific user. By buffering changes for a specific user in-memory we were able to massively reduce the number of times we read or write Dynamo records. And by later enforcing a Least Recently Used policy on our write buffer we were able to further reduce not only our storage usage but also our average in-memory cache size.
Impact: By doing this work up front we have been able to more easily evolve our personalization models and create new features, like personalized vocabulary practice. In fact, running A/B tests for grammar and vocabulary models at the same time with these improvements is now 50% cheaper than even running the original grammar model alone.
Question 3: How do we make English certification testing more accessible?
Problem: How do we ensure accurate, bias-free proctoring of the Duolingo English Test (DET) online?
English certification tests are both prohibitively expensive ($200+ in most countries for the TOEFL) and physically inaccessible in terms of location for many English learners worldwide, especially those in remote locations. In order to make English certification more easily accessible, we developed the DET, which is administered online and costs only $65. Although human proctors administer the DET, there’s opportunity for human error due to fatigue as well as bias.

Solution: Develop a system for AI-assisted human proctoring.
Bias in humans is very, very difficult to fix. However, when using the right training data with AI, reducing bias is much easier. This is why the DET always uses a combination of both human proctoring and a suite of computer vision models in each test.
The models work through object detection (e.g., detecting prohibited items like headphones which can be used to feed test takers answers), eye gaze detection (e.g., analyzing where test takers’ eyes are focused and for how long they’re looking away from the screen), and even simply ensuring that test takers’ full faces and eyes are shown clearly. The computer vision models surface events to help alert the human proctors to potential cheating, which the proctors can evaluate and act on.

The challenge of bias can be mitigated by training models with data representative of what is seen in production. This means carefully picking a training dataset that is representative of the test taker population, accounting for variables ranging from racial distribution, to signals affected by economic conditions (e.g. resolution of the camera), and even things like lighting conditions of the room in which they are taking the test. We also need to analyze bias in the output via statistical analyses such as differential item functioning (DIF), and to ensure that the performance of the model does not degrade over time (also known as model drift) using monitoring tools in production.
Impact: The impact is more control over bias and reduction in human error while proctoring the DET. AI helps ensure that there is more efficient and consistent decision making, which reduces cost and helps us keep the DET five times less expensive than our competitors. The result is increased access to an English certification test (and by that token, higher education) for English learners all over the world.
There’s more to solve!
If these problems seem interesting to you, we want you to help us solve them and achieve our mission!
Many thanks to: Klinton Bicknell, Em Chiu, André Horie, Reid Kilgore, and Anton Yu for their help with this post!