
Have you ever wondered how Duolingo figures out whether your answer counts as right or wrong? Let’s say you’re learning Portuguese and get “Eu tenho gatos demais” (literally I have cats too many) so you type “I have too many dogs.” You’ll get a red ribbon and a sad Duo. How does Duolingo know? Although this example is pretty simple, deciding which translations should be accepted turns out to be a complex problem!
In this post, we’ll talk about why translation grading is so hard, and we’ll report on a recent research project we organized to develop sophisticated artificial intelligence solutions to this problem.

How many ways can you say the same thing?
Our method for grading is to compare each learner response against a list of acceptable translations curated by expert translators. You can see an example of all the English translations of a Portuguese sentence here:

The number of translations can become huge depending on the length or complexity of the sentence. In one sentence in the English course for Chinese speakers – “Unfortunately, someone put my wool sweater in the dryer” – the number of Chinese translations reached over 6 billion! In that case, the many vocabulary options and possible word orders compounded to create this massive number. This can be a huge burden on our translators!
Not all sentences have this extreme number of translations, of course, but many still number in the hundreds. For humans, generating all of these translations is time-consuming, and it slows down course creation. If we could accelerate this process using techniques from Natural Language Processing (NLP), we could help speed up the creation of new learning content and new courses, and ultimately improve the experience for our learners!
One way we are tackling this problem is by organizing a “shared task” called STAPLE: Simultaneous Translation and Paraphrase for Language Education. A shared task is a hands-on project with real data and real questions, in which many research groups work on the same task separately over the course of several months, ultimately meeting together at a conference to compare and contrast results. It is the research community’s equivalent of a chili cookoff. By this analogy, we provide the main ingredients (beans, beef, etc.), the teams season them and slow cook them according to their own machine-learning recipes, and we judge the flavor.
What was the STAPLE task?
The goal of the STAPLE task was for participants to take a list of sentences, and use computer models to produce all acceptable translations for each one – exactly the same task that our human translators currently do.
There are two competing challenges in this task: first, you want to produce correct translations. It won’t do if the sentence is “Eu sou um menino” and the predicted translations are “I am a dog” or “I am a banana.” Second, you want to produce complete translation sets (or as complete as you can). If the sentence is “Eu sou um menino,” it’s insufficient to produce only “I am a boy.” You would need other correct translations, such as “I’m a boy” and “I am a child.”
You may be wondering why we can’t just use Google Translate to solve this task. The short answer is that Google Translate is designed to produce only a single translation per sentence, in part because it is trained with generic translation data, which has only a single target translation for each source sentence (left side of the figure below). There are very few, if any, public datasets with many target sentences for a single source sentence (right side of the figure).

Fortunately, this is exactly the kind of data Duolingo has, since we use multiple translations in our courses! In the STAPLE task, we provided translations from the courses that teach English to speakers of Hungarian, Japanese, Korean, Portuguese, and Vietnamese – languages chosen because of their diversity of grammar, writing systems, and learner popularity. This unique data set is now available to the public online.
What did participants do?
Teams from all over the world participated in this shared task, and they ranged from individual researchers, to graduate students, to large research groups.
Most participants took a two-step approach: 1) first using millions of pairs of source and target sentences to train a generic machine translation model, and then 2) using our STAPLE data — with each sentence having multiple translations — to teach the model how to generate multiple correct outputs.
What varied most across the teams was the kinds of data they used in each step. For step 1, different teams used different training data, from such diverse sources as the European Parliament proceedings, movie subtitles, and educational sentence collections. For step 2, there were many ways to teach the model how to use multiple target translations, but some of the best models paid special attention to how often learners responded with each possible translation. So even when multiple translations should be correct, certain translations are more likely than others.
What were the results?
Any good task needs to have a way to measure how well each participant did, also known as an evaluation metric. We used a metric called Weighted F1 Score (based on F-measure) that gave credit to participant predictions according to a combination of correctness and completeness. A score of 0.0 means that the system failed completely, and a score of 1.0 means the system is perfect.
The bar graph below shows the performance of a commercial machine translation system (Amazon Translate) alongside the performance of one of the best-performing teams. The top scores were around 0.55, which are good, but far from perfect.
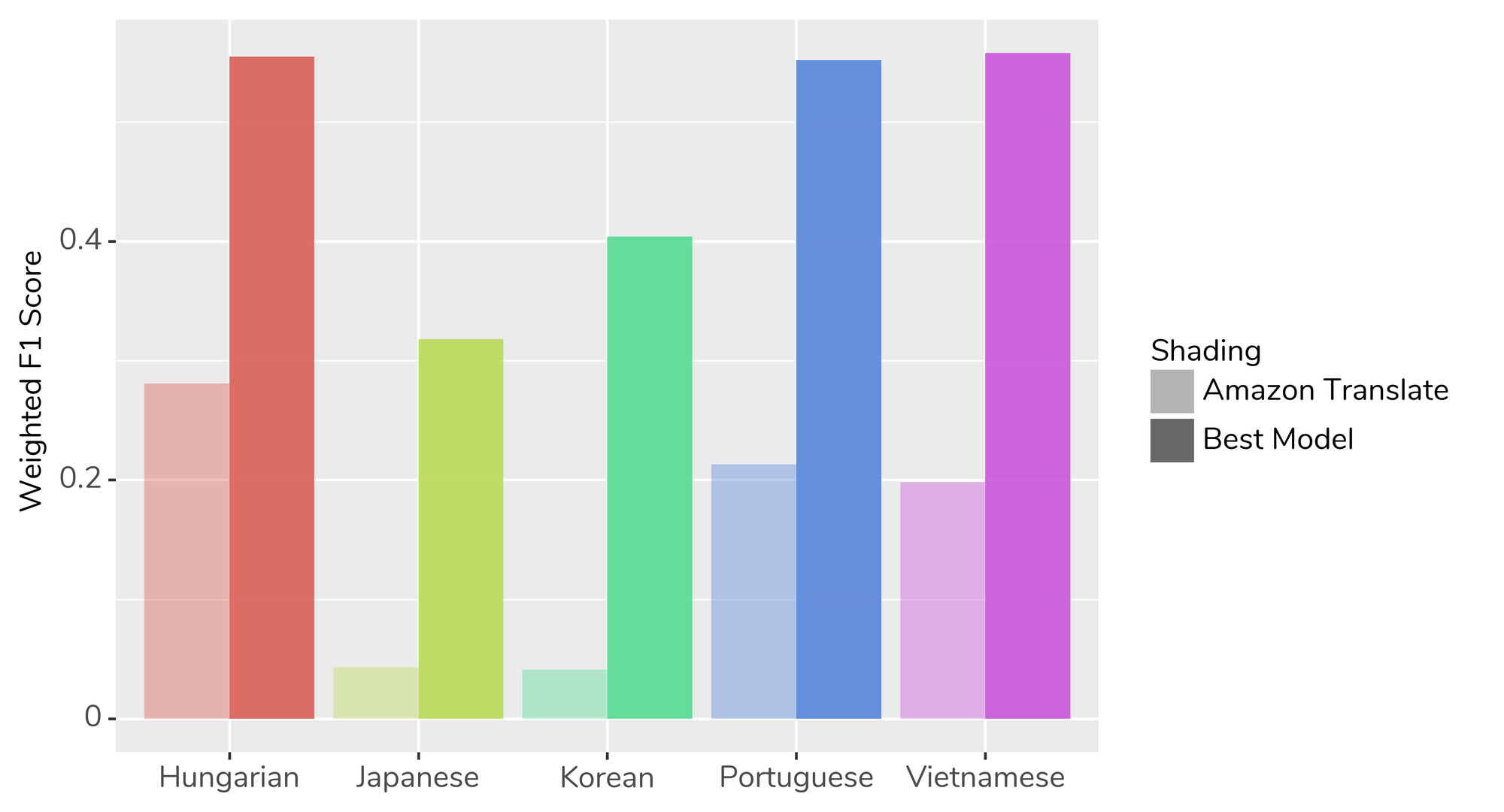
The graph also shows us a couple of other interesting things:
First, the best model dramatically outperforms Amazon Translate. This is because Amazon Translate provides only a single output (although, under the hood it may generate many translations), whereas our STAPLE task requires many outputs.
Second, the winning team accounted for translations in some languages much better than in others. For example, the many levels of formality in Japanese and Korean led to surprisingly high numbers of translations per sentence in the reference data (the answer key), and participants tended to produce far too few translations.
What’s next?
This shared task generated a lot of interesting research on translations, with implications not only for Duolingo, but also for the research community at large. We’ve publicly released the full STAPLE dataset, and we are excited to see how researchers use this unique data in new projects!
We’re looking forward to using this research to create powerful tools for our course creators and translators. Our STAPLE task is a great example of how humans and computers can work together to develop systems that are more efficient and friendlier to the humans that use them – and more effective for our language learners. We’re already working on building a dedicated translation tool, and these research projects could also be used to build autocomplete or translation suggestion tools, making our translators’ experience much faster and smoother.
To learn more about this task, take a look at our 2020 Duolingo Shared Task website, which includes links to the data from our overview paper, and papers from all participants.
