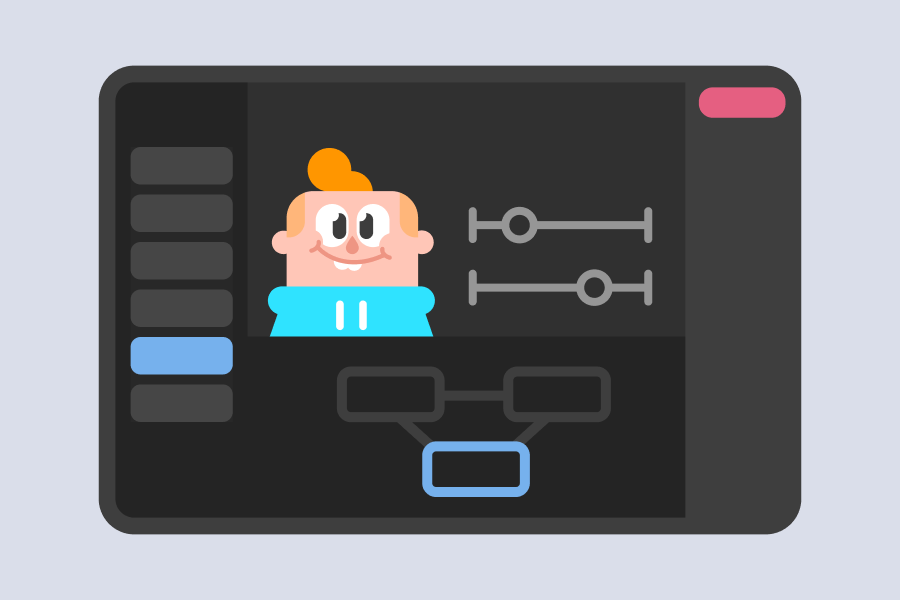
After developing the individual voices for each of the characters, we thought about how to bring them to life – beyond the animations with idle behavior that we had. We wanted to ensure our characters were lively, engaging study buddies for our learners!
First: That’s a lot of mouth movements to animate!
We teach more than 40 languages across more than 100 courses, each containing thousands of sentences and lessons, so manually animating the lip movement for our ten World Characters was completely out of the question. We needed something scalable to account for any possible combination of mouth shapes for each character to correspond with the sounds, while keeping the file size small enough to run on Android, iOS, and the Web. Plus, we wanted to ensure that our animation quality was not compromised in the process!
We thought the answer might lie in an alternative to a game engine —something that can help us take a limited number of assets and turn those into a virtually unlimited number of combinations. This is how we learned about Rive!
What is Rive?
Rive is a web-based tool for making real-time interactive animations and designs, similar to a game engine. It seemed to solve so many of our problems: The file sizes were compact and plugged in neatly with Duolingo’s app architecture, and the handoff from animator to engineer was seamless.
But what stood out to us was Rive’s State Machine: a visual representation of the logic that connects the animations (“states”) together. That means it allowed us to programmatically control which animation states are called, how they are called, and how they transition and blend together. The State Machine’s powerful system is what allowed this project to be feasible on a grand scale. We knew Rive was the right tool to bring lip syncing to life!
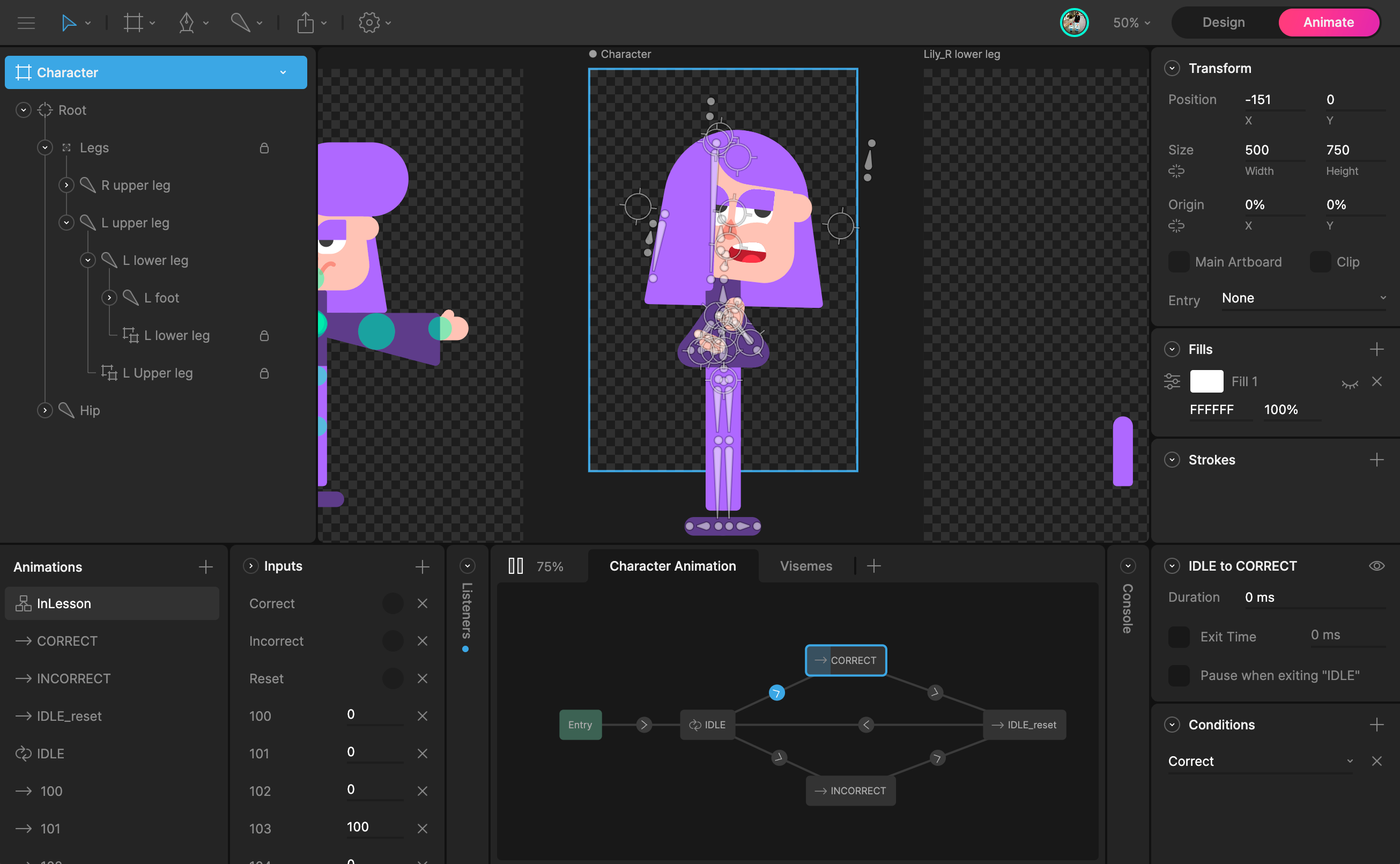
The magic of speech technology
To make the mouth movements, we need to know what is happening in the speech in fine detail. When we built the voices for text-to-speech, the solution we used didn’t give us pronunciations and timing for what was being said–but we have a rich speech technology ecosystem that we set up for language learning. To create accurate animations, we generate the speech, run it through our in-house speech recognition and pronunciation models, and get the timing for each word and phoneme (speech sound). Each sound is mapped onto a visual representation, or viseme, in a set we designed based on linguistic features.
With these capabilities, we built a factory to generate all the viseme timings we needed for our course content. Of course, we also needed to make sure it was correct, and to get the information to the right place, for millions of users. We built up the tools and processes not only to generate the material, but to audit and correct it when we need to.
Designing a world of mouth movements
Before we could start animating, we had to make sure that we accurately represented the mouth shapes that correspond to specific sounds.

We had to design each mouth shape in a way that remained faithful to our Duolingo aesthetic. On top of that, each character needed their own set of shapes for each viseme that followed their unique personalities. The most critical part of the design process was ensuring that the viseme designs looked believable when animated.
Once there was a design guide in place, we could move onto animation. We created an animation state for each character’s general poses in the lesson, but we also made separate states just for the character’s mouths. After all the animation states were set up, the only step left to do was to plug these animations into Rive’s State Machine and combine them with the mouth inputs we annotated earlier.
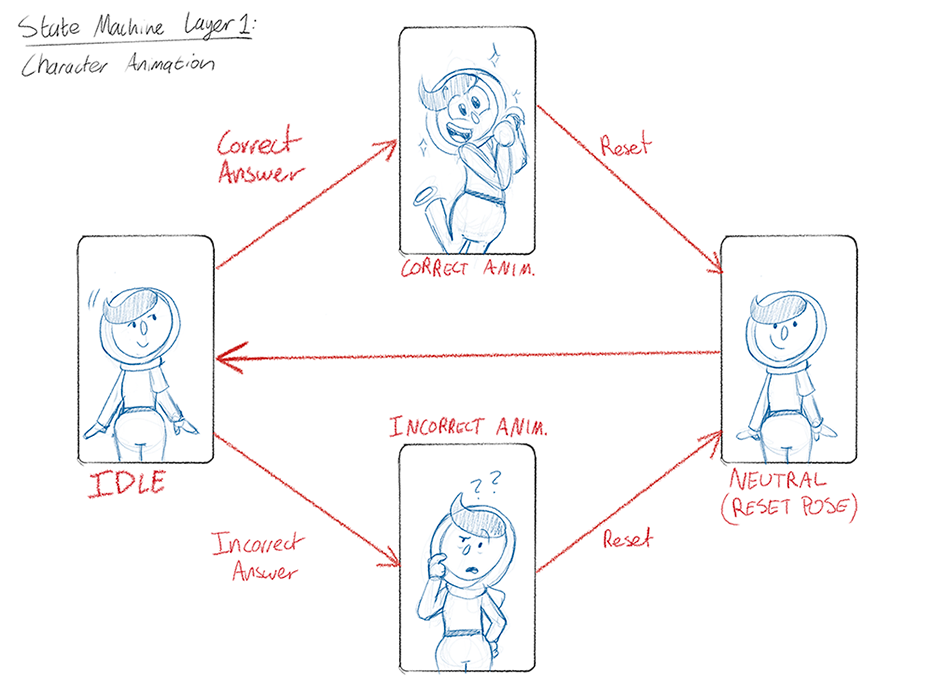
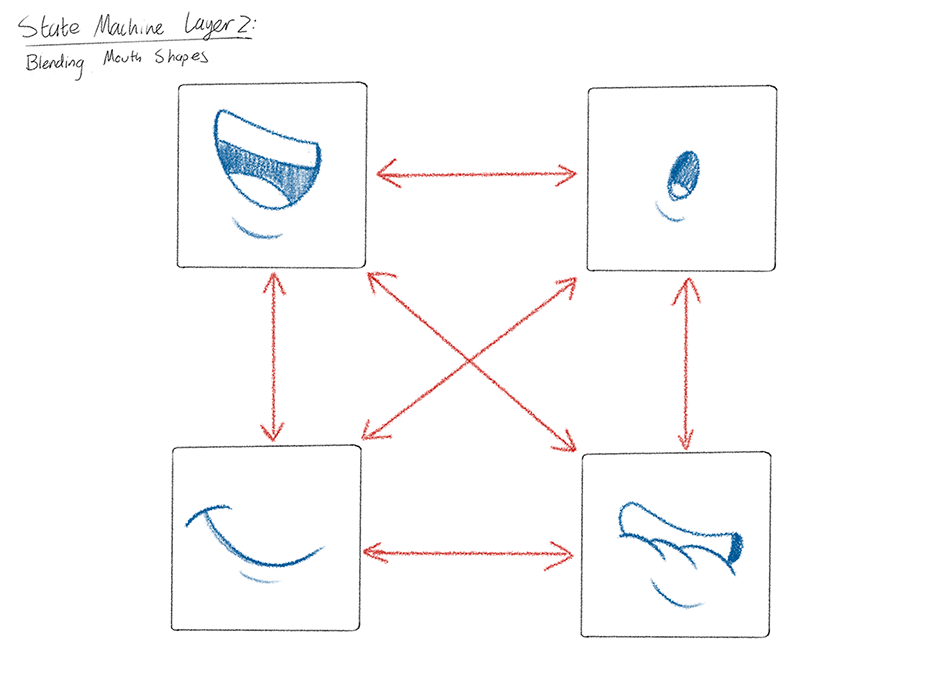
After the State Machine setup is finished, it is exported from Rive into a single runtime file, then handed off to the engineers so that they can integrate the animations into the app!
Putting it together
When the time comes to show a challenge, we retrieve the audio and the timing information, and then use the timings to trigger the animation state machine in sync with the audio. This keeps the data transfer to an absolute minimum – much less than sending down a little movie – and lets us react to what the user does in real time. When you click on a word, the character will say and animate that word; if you finish the exercise before it is done speaking, the character will stop speaking in time. We can also show idle behavior like head nods, blinking, and eyebrows moving. Finally, based on the outcome of the challenge – if you get it right or wrong – we can move to a final state, showing the reaction to your response!
The future of animation and technology at Duolingo
Duolingo strives to test everything, and these mouth movements are no exception. This project was a fun experiment in making the learning experience more engaging, and a chance to use new software and technology for the production pipeline. It’s been enlightening to see what can help us to overcome technical challenges so that we can continue to make or polish other delightful features for the app!
Check out our 2023 Duocon talk to learn more about our approach to animation!